Zombie & Orphan process
Zombie process는 defunct process라고도 부르며, 종료를 했지만 운영체제가 내부에서 관리하는 프로세스 테이블에서 아직 종료되지 않았다고 인식되는 프로세스를 Zombie 프로세스라 한다. 사실 종료되지 않았다고 인식되는 것은 아니고 그냥 남겨두는 것인데, PARENT Process가 CHILD의 pid를 알 수 없어서 좀비상태로 놔두는 것이다.

예시를 보면 child 프로세스는 1초만에 먼저 종료된다. 그리고 부모 프로세스는 30초간 대기하고 종료되는데, parent는 child의 상태값을 가져가야 하기에 좀비 상태로 두는 것이다. 의도하지 않은 많은 좀비 프로세스는 시스템을 망가지게 하므로 조심해야 한다.
Orphan process는 고아 프로세스이다. 좀비와 반대로 부모가 먼저 종료된 자식 프로세스를 말한다.
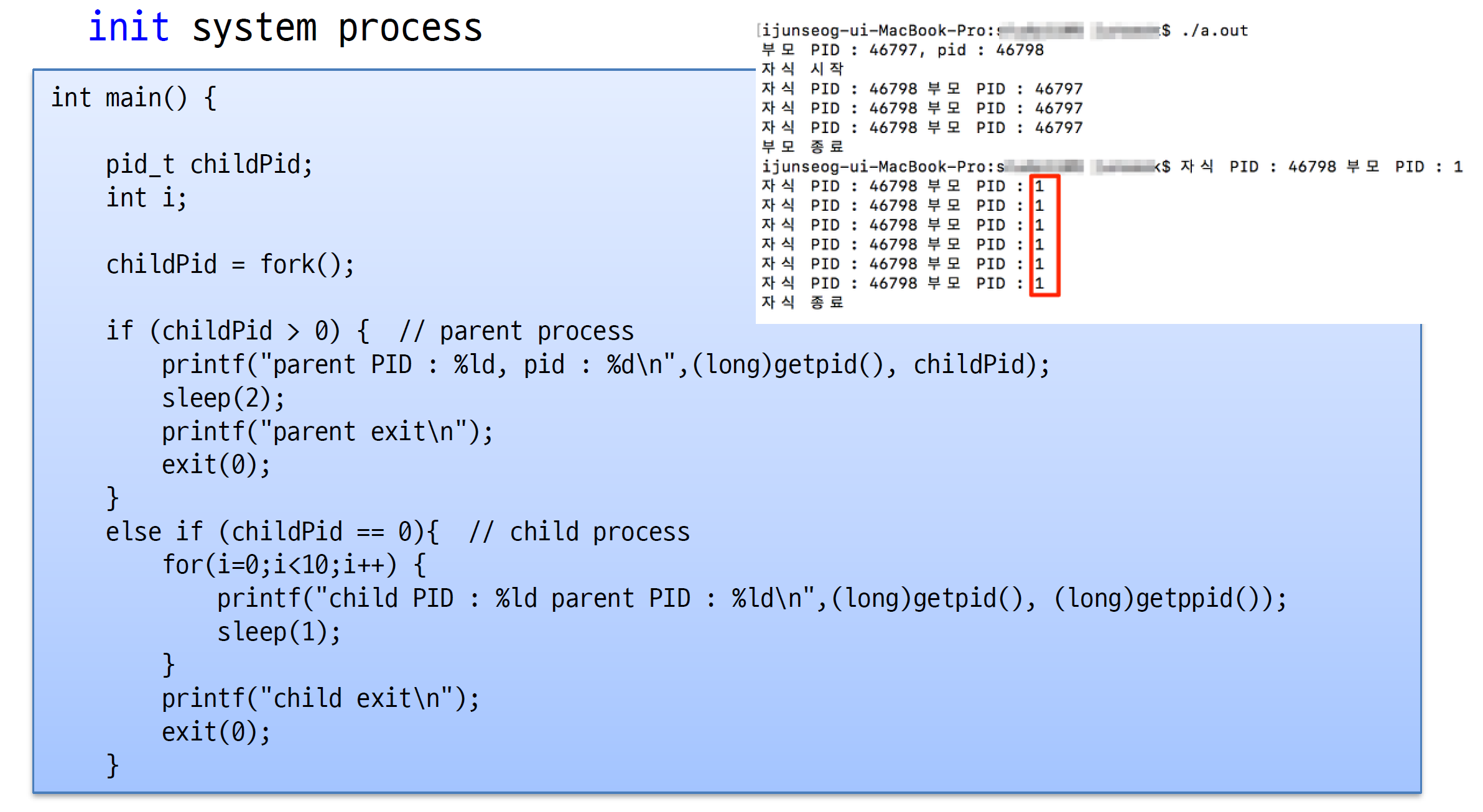
예시를 보면 부모 프로세스가 먼저 죽게되버리면 자식은 부모가 없어져버리는 상황이 된다. 그런 일이 벌어지면 자식 프로세스를 init 프로세스의 자식으로 입양하게 된다.
Pocess State Transition
운영체제 입장에서는 굉장히 많은 프로세스가 한 번에 돌고있다. 운영체제는 이들을 어떻게 관리할까?
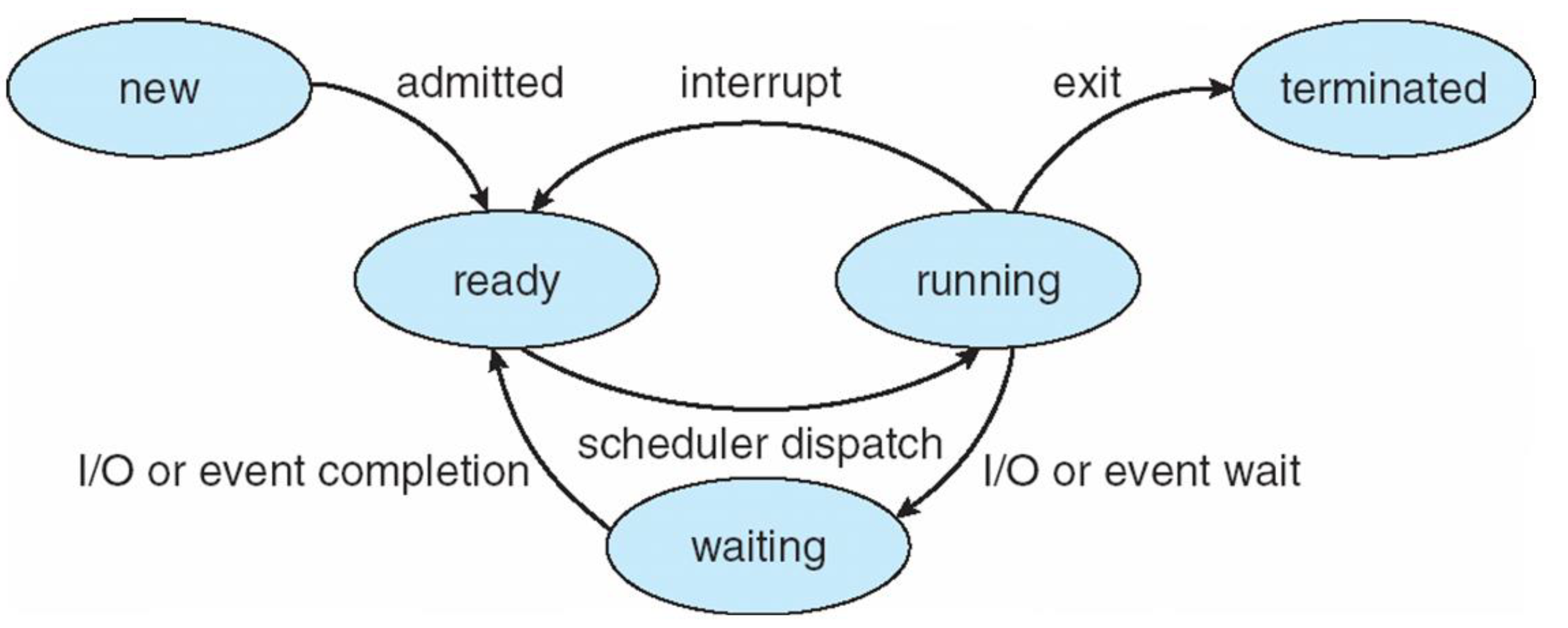
프로세스는 상태가 변하면서 돌게 된다.
- 초기 상태의 프로세스는 new 상태이다. new 상태인 프로세스는 address space를 만들고 PC를 세팅하는 등 CPU를 쓸 준비를 한다.
- 프로세스를 ready 상태로 만든다.
- 프로세스를 running 상태로 만들고 그 프로세스에 CPU를 할당해준다.
- 그리고 프로세스가 CPU를 너무 많이 쓴다던가 인터럽트를 받는다던가 하면 CPU를 뺏어서 ready 상태로 만든다.
- running → ready 상태를 반복하다 exit된다.
- 프로세스가 I/O 장치를 기다리는 등 CPU를 사용하지 않아도 되면 waiting 상태로 바꾸게 된다. 그러다 I/O가 끝나면 다시 ready로 바꾸고 running으로 만든다.
즉 ready running wating을 반복하다 종료하는게 프로세스의 생명주기이다.
PCB
이런 상태들을 운영체제가 잘 관리해야 하는데, PCB, Process Control Block 이라는 구조체 같은걸로 관리한다.
PCB는 프로세스에 관한 모든 정보를 가지고 있는 구조체이다. PCB는 한 프로세스를 뜻하기도 한다. 프로세스가 3개라면 운영체제는 PCB 3개를 관리하고 있다. 그러면서 해당 프로세스가 어떤 상태에 있는지 관리하는 것이다. 실제로는 상태 정보 뿐 아니라 아래의 정보들도 관리한다.
- Process state
- Program counter
- CPU registers
- CPU schduling information : CPU를 얼마나 썼는지 등의 정보
- Memory management information
- Accounting information
- I/O status information, 등등 굉장히 많음
Linux에서는 task_struct에 정의되어 있는데, 1K가 넘을 정도로 많은 정보가 들어있다.
실제로는 리눅스에서 이런 task_struct(TCB)를 doubled linked list로 되어있는 task list로 관리한다. task list를 잘 뒤져보면 모든 프로세스의 정보가 다 있다.
Context Switch
PCB와 하드웨어 상태를 잘 생각해봐야 한다. 프로세스가 running 상태라는 것은 CPU(PC, SP, registers)를 사용하고 있고 하드웨어가 값을 가지고 있다는 것이다.
만약 running 상태인 프로세스를 waiting 상태로 만들어야 한다면, PC값을 포함한 CPU의 상태값들을 반드시 저장해야 한다. 다시 프로세스가 running되면 복원해줘야하기 때문이다. 그런 값들을 PCB에 저장하게 된다.
프로세스를 waiting 상태에서 다시 running 상태로 변경하게 되면 위의 과정들을 거쳐야하는데 이 과정을 Context Switch라 한다. 혹은 process switch라고도 한다. process switch의 뜻은 알겠는데 Context는 뭘까?
여기서의 Context는 CPU의 레지스터, 메모리 등의 자원들을 뜻하고, Context를 저장하고 로드하기에 Context Switch라 한다.
즉, Context switch는 CPU를 하나의 프로세스에서 다른 프로세스로 바꾸는 과정을 말하며 컨텍스트 스위치를 하려면 오버헤드가 들어간다.(부담스러운 일이다.)
Context switch는 레지스터, 메모리를 저장했다가 복원했다가 하는 일을 해야하고 컨텍스트 스위칭이 일어나면 캐시도 미스가나서 다시 바꾸고, 히트가 나고 이런 캐시와 관련된 작업도 수행해야한다. 따라서 굉장히 힘든(overhead)한 작업이다.
그런데, 이 컨텍스트 스위치를 하드웨어가 도와줄 수 있다면 훨씬 간단해진다. 예를 들어 UltraSPARC는 레지스터 set이 멀티이다. 따라서 레지스터를 저장했다가 복원할 필요할 가능성이 줄어든다. 따라서 컨텍스트 스위치는 쉬워지지만 하드웨어는 비싸지고 한계가 있다.
다시 Context switch를 정리하자면 P0 프로세스가 실행중이다가 인터럽트나 시스템 콜이 들어오면 운영체제가 PCB0에 CPU의 상태값들을 저장한다. 그리고 P1 프로세스를 실행해야지 라고 판단했다면 PCB1의 값들을 다 꺼내서 CPU에 덮어쓴다. 로딩이 끝나면 P1 프로세스를 돌리고 멈추는 과정을 계속 반복한다.

save state into PCB0 ~ … ~ reload state form PCB1 까지의 과정을 Context Switching이라 한다. 컨텍스트 스위칭은 매우 매우 매우 중요하고 time sharing 방식으로 멀티 프로그래밍이 가능하게 하는 원리이다!
context switch는 overhead가 많이 들어가는 작업인데, 그럼에도 context switch를 해야하는 이유는 대부분의 어플리케이션이 I/O를 포함하기에 그 시간에 context switch를 해서 다른 프로세스가 CPU를 사용할 수 있도록 하기 위해서이다.
Process State Queues
- 운영체제는 여러개의 프로세스를 잘 관리해야 한다. 운영체제는 Process State Queues라고 하는 여러 개의 큐를 가지고 관리한다. 예를 들어 ready 상태인 프로세스를 위해서 ready queue를 사용한다. wait queue도 있는데 어떤걸 기다리는지에 따라 여러 타입의 wait queue를 만든다.
- 상태 큐는 각각의 PCB 정보를 포함하고 있다.
- 프로세스의 상태가 변함에 따라 PCB는 다양한 큐들 사이를 옮겨다닌다.
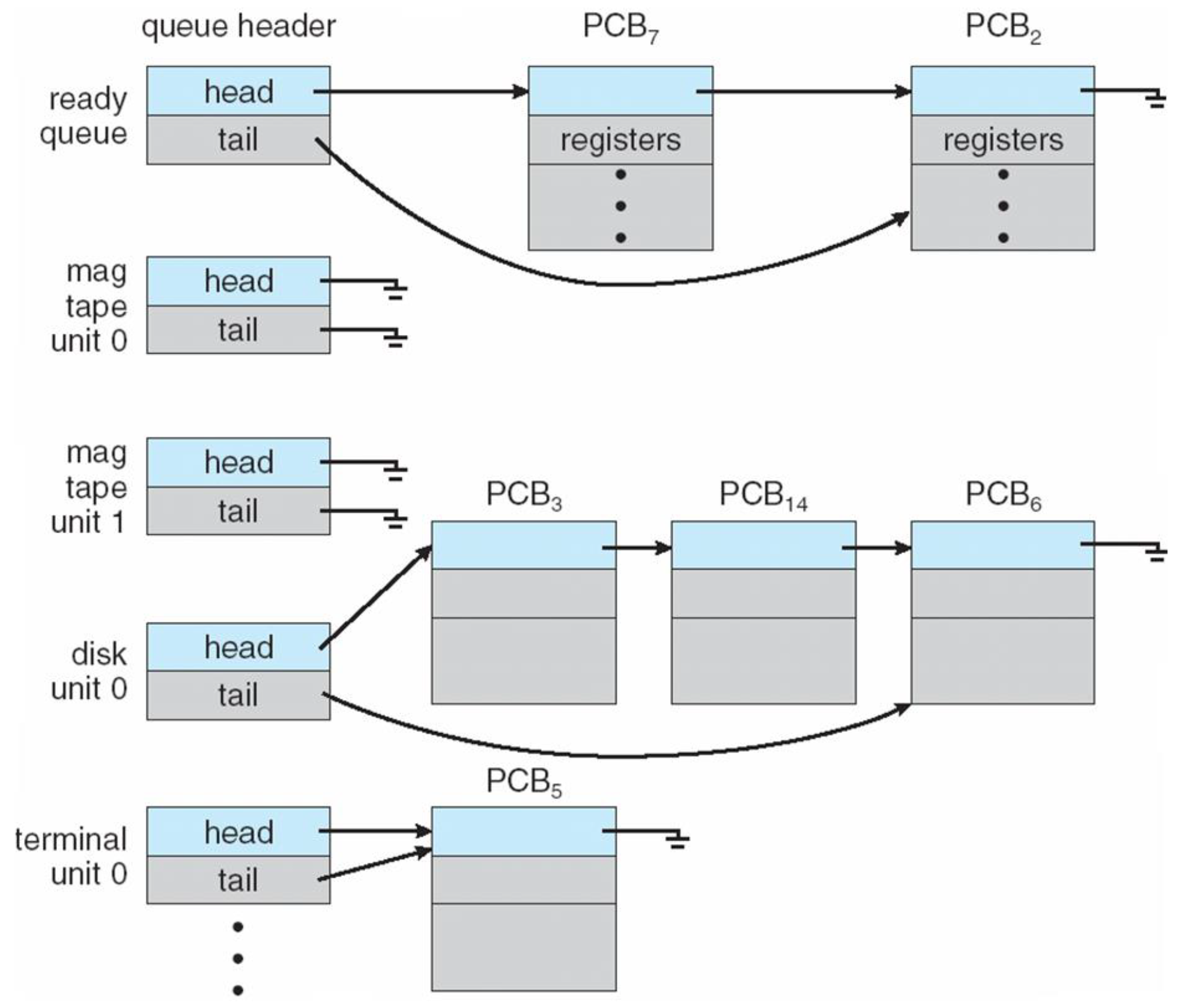
wait큐에 있던 프로세스를 ready큐에 넣어야 한다면 포인터만 딱딱 바꾸면서 쉽게 관리할 수 있다.
- PCB는 OS 메모리 안에서 동적으로 할당되는 자료구조이다.
- 프로세스가 만들어지면 OS는 PCB를 위해 메모리를 할당하고, PCB를 초기화하고 적당한 큐에 넣게 된다.
- 프로세스가 종료되면 OS는 PCB에 할당된 메모리를 해제하면서 종료하게 된다.
Process Creation: UNIX
int fork()
- fork가 호출되면, PCB를 만들고 초기화한다. 그리고 새로운 address space를 생성, 초기화하고 부모 프로세스의 memory space를 복제한다.
- 부모에서 사용된 추가적인 커널 리소스들을 초기화한다.
- 그리고 PCB를 레디 큐에 넣는다.
- child's PID를 부모에게 리턴하고 child에게는 0을 리턴한다.
int exec(char *prog, char *argv[])
- 현재 프로세스를 멈춘다.
- "prog" 프로세스를 address space에 로드한다.
- 기계 코드와 스택, 힙, PC 등의 address space를 모두 초기화해서 세팅해준다.
- exec()는 새로운 프로세스를 만들지 않는다는 사실을 주의하자!

쉘의 간단한 예시를 보자. 리눅스의 대부분의 명령어는 사실 실행 파일이다. cat, ls, mv들은 모두 하나의 프로그램으로 만들어져 있다. 쉘과는 별도이다. 쉘은 이 실행 파일을 불러서 실행시키는 역할만 한다. exec라는 명령어를 쓰면 코드와 데이터 부분을 ls에 맞게 덮어쓴다.
exec는 새로운 프로그램으로 변신하게 해준다. fork와는 다르게 새로운 프로세스를 만들어주진 않고 덮어쓰는 것이라는 사실을 주의하자.

프로그램을 띄우는 원리는 fork와 exec를 잘 섞어 사용해서 새로운 프로세스가 다른 역할을 하도록 하는 것이다.
BOOL CreateProcess(char *prog, char *args, …)
fork()와 exec()를 동시에 부른 것과 유사하게 동작한다.
Why frok()?
왜 fork를 사용해서 프로세스를 만들어야할까? fork는 굉장히 유용하다. 특히 child와 parent가 같이 협조해서 동작해야 하는, parent의 권한이나 자원을 받아서 동작해야하는 경우에 유용하다. 즉, 병렬 프로그래밍이 가능하기에 fork가 중요하다.

예를 들어 웹서버가 80번포트로 요청이 들어온다면 fork()를 한다. parent는 소켓을 닫고 다시 대기 상태로 돌아간다. child는 소켓 번호에 요청에 맞는 핸들링 후 응답한다.
여기서 포인트는 소켓의 번호인데, 소켓의 번호는 parent와 child가 모두 알아야 한다. 즉 parent의 자원(소켓 번호)을 child가 알아야 하고 child는 요청 작업이 끝나고 없어지면 좋다는 것이다.
많은 요청이 동시에 들어오면 parent는 child만 많이 만들어주고 계속 다른 요청을 대기할 수 있으므로 fork 방식이 유용하다.
Inter-Process Communication
fork() 로 만든 새로운 프로세스와 부모 프로세스가 서로 참조하고 싶을 수 있다. 그런데 자식 프로세스와 부모 프로세스는 서로 다른 메모리 공간을 사용하기에 서로를 참조할 수 없다. 프로세스간에 대화가 필요하면 Inter-Process Communication 을 하면 된다.
Inside a machine
- pipeline
- FIFO
- Shared memory
- Sockets
Across machines
- Sockets
- RPCs
- Java RMI
'CS > Operating System' 카테고리의 다른 글
| [OS] 프로세스와 쓰레드의 비교, pthreads, Signal handling (1) | 2024.04.11 |
|---|---|
| [OS] 프로세스의 단점과 쓰레드의 도입, 멀티 쓰레딩의 장점 (0) | 2024.04.09 |
| [OS] 프로세스의 개념과 생성, fork 시스템 콜 (0) | 2024.04.02 |
| [OS] I/O에서 데이터 전송 방식과 Timers, Protected Instruction (1) | 2024.04.01 |
| [OS] 운영 체제의 내부 구조와 이벤트들 - Interrupt, Exception, Signal (1) | 2024.03.31 |