1. Demand Paging
Demand가 있을 때 Paging을 시키겠다는 개념이다. 메모리가 정말로 필요한 순간에 가상 페이지를 피지컬한 메모리에 할당한다.
- 피지컬한 메모리와 디스크를 왔다갔다하는 I/O 횟수가 줄어든다.
- 피지컬한 메모리의 필요량이 줄어든다.
- 응답이 빨라진다.
- 좀 더 많은 프로세스를 수용할 수 있다.
OS가 메인 메모리를 마치 캐시처럼 사용한다.
- 메모리를 디스크의 캐시처럼 사용한다.
- 프레임 단위로 디스크에 내리거나 필요한 게 있으면 메모리로 올려서 사용하는 방식이다.
- 피지컬한 메모리가 다 차게 되면, 메모리가 부족해진 것이므로 적절한 프레임을 찾아서 디스크로 내린다.
- 디스크로 내리는 과정을 Eviction이라 하고, 반대의 과정 메모리로 올리는 것을 loading이라 한다.
디스크로 내리는 과정을 보자.
- 디스크로 내려서 eviction 시켜야 할 때 해당 프레임이 읽기만 해서 clean 상태인지, 뭔가가 write가 일어나서 dirty 상태인지 modify bit로 알 수 있다.
- 만약 dirty 상태라면 디스크에 반드시 써야한다. 메모리와 디스크의 내용이 다르기 때문이다.
- clean 상태라면 굳이 다시 쓸 이유는 없다. 그냥 페이지 테이블과의 매핑을 끊어버리면 된다. 이렇게 evited된 PTE는디스크를 가리키고 있다.
- 따라서 dirty인지 아닌지 확인하는 것이 중요하다. 디스크에 쓰는 것은 굉장히 오래걸리기 때문이다.
- 운영체제는 알아서 메모리에서 디스크를 왔다갔다하면서 eviction, loading을 수행한다.
- Transparent to the application : 어플리케이션은 이 페이지 교체 작업을 전혀 몰라도 된다.
2. Page faults
evicted page virtual address로 요청이 왔을 때 즉, valid bit가 0인 페이지에 요청이 들어오면 해당 페이지는 피지컬한 메모리에 존재하지 않는다. 그런 페이지에 대해 요청이 있는 상황을 page faults라 한다.
- ecvition이 일어날 때 valid bit를 0으로 만들고 해당 페이지가 디스크의 어디에 있는지 적어놓는다.
- 그리고 이 페이지에 접근하면 exception이 발생한다.
그리고 운영체제에 있는 코드인 page fault handler가 작동한다.
- page fault handler는 디스크(swap file)에서 요청이 들어온 데이터가 어디있는지 찾는다. 그리고 읽어서 메모리에 적는다. 이 과정에서 disk I/O가 발생한다.
- 그리고 페이지 테이블을 업데이트 시킨다. valid bit를 1로도 만들고 기존에 어딘가를 가리키던 페이지를 새로 메모리로 바꾸는 과정이 일어나는 것이다.
- 위의 핸들러 과정이 다 끝나면 처음부터 다시 요청한다.
페이지를 다시 올릴 땐, 보통은 메모리가 꽉차서 해당 페이지가 내려가 있었던 것이다. 따라서 다시 페이지를 올릴 때 어떤 프레임을 빼서 새로운 프레임을 올릴것인지 문제가 된다.
- 앞으로 사용되지 않을 프레임을 빼면 된다. 이를 replacement algorithm이라 한다.
- 기본적으로 운영체제는 빈 프레임을 유지한다. 사실은 메모리가 꽉 차서 내리는건 아니고 빈 프레임을 유지하기 위해 내리는 것이다.
- 그럼 운영체제가 적절한 빈 프레임을 얼마나 유지할까? 보통은 빈 공간을 10% 정도로 유지하는데, 이것도 고민이 된다.
참고) 페이지 테이블은 프로세스가 종료될때까지 변하지 않는다. 디스크를 가리키는지 메모리를 가리키는지만 변하는 것이다.
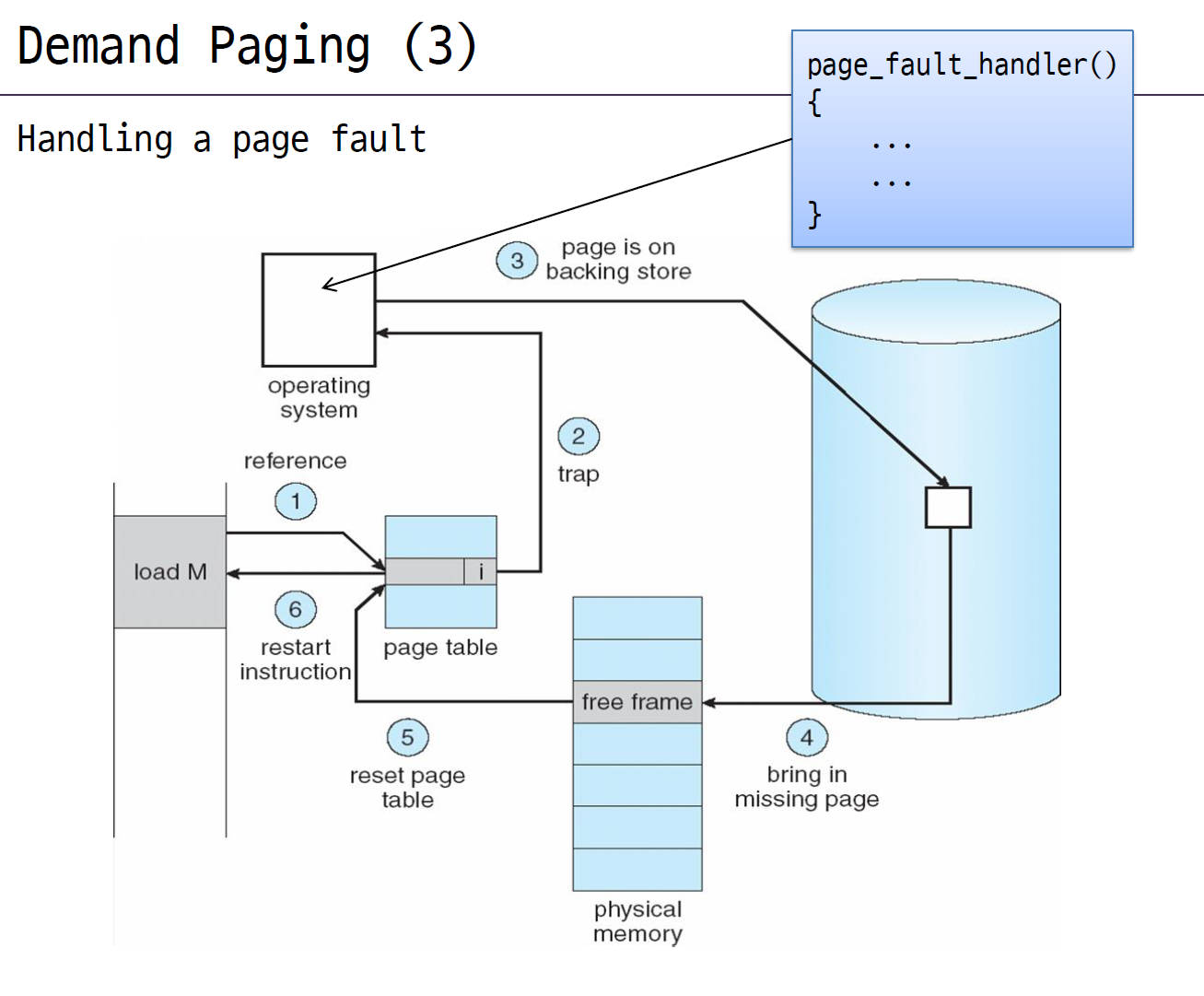
페이지 폴트가 일어나는 과정을 다시 정리해보자.
- 프로세스가 가상 주소로 요청한다.
- 가상 주소로 페이지 테이블에 엑세스했더니 해당 페이지의 vaild bit가 0이다. 그렇다면 trap, exception이 발생한다.
- 운영 체제 코드로 넘어오고 운영체제는 page fault handler 함수를 호출한다.
- 내가 원하는 프레임이 디스크의 어디에 있는지 찾고, 찾은 파일을 읽어서 빈 프레임에 쓴다. (I/O)
- 페이지 테이블을 다시 세팅하고 valid bit를 1로 만든다.
- 아까 요청한 주소를 다시 요청한다.
Why does this work?
Locality
- Temporal locality : 한 번 엑세스된 메모리 위치는 조만간 다시 엑세스할 확률이 높다.
- Spatial locality : 한 번 엑세스된 메모리 근처는 다시 엑세스할 확률이 높다.
로컬리티때문에 페이지 교체가 그렇게 많이 일어나지는 않는다.
- 페이지 디맨드는 메모리를 적게 쓰면서도 메모리에서 hit가 날 확률을 높여주는 장점이 있다.
- 평균적으로 paged in된 페이지를 주로 사용할 것이다.
- 하지만 이는 여러 사항들에 의존적이다.
- 어플리케이션의 로컬리티 정도
- 페이지 리플레이스먼트 알고리즘이 잘 짜져있는지
- 피지컬한 메모리의 양
- 어플리케이션의 참조 패턴
왜 "demand" paging일까?
demand 용어에 대해 다시 생각해보자. demand가 생겼을 때 메모리에 올려놓겠다는건데, 프로세스가 새로 만들어지면 페이지 테이블만 만들어놓고 아무 프레임도 할당해주지 않아도 된다. valid 상태가 다 0이고 아무 화살표도 연결하지 않은 상태인 것이다.
처음엔 당연히 miss가 날 것이다. 프로그램의 코드를 포함해서 아무것도 할당되지 않았기 때문이다. 따라서 당연히 page fault가 난다. 이런 상황을 cold miss/cold page fault라 한다.
그러다가 메모리를 더 쓰게 되면 또 page faults가 날거고 그때 디스크에서 찾아서 메모리에 할당한다. 이게 demand paging이다.
이 방식은 프로세스가 생성되면 페이지 테이블만 만들면 되고, 필요한 만큼만 채워진다는 장점이 있다.
프레임의 할당이 쓰는 만큼만 일어나기에 메모리를 아낄 수 있다.
cold miss 이후에는 로컬리티덕분에 잘 동작할 것이다.
2. Segmentation
코드, 스택, 힙, 라이브러리 등의 논리적으로 연관된 데이터 유닛을 묶어서 하나의 세그먼트로 할당하는 것이다.
- 스택 세그먼트 따로, 메인 프로그램 세그먼트 따로 그런식이다.
메모리를 variable-sized segments의 컬렉션으로 보는 방식이다.
- Varaible-size partitions와 유사하지만 한 프로세스에 한 세그먼트가 아닌, 한 프로세스에 여러 세그먼트트 사용하는 것이다.
- 세그먼트들을 ordering 할 필요는 없다.
- 세그먼트를 사용한 가상 주소는 <Segment # :: Offset>가 된다.
세그먼트는 사이즈가 늘었다 줄었다 변할 수 있다.

세그먼트를 위해서는 segment table이 필요하고, 그 테이블에는 세그먼트의 수만큼 엔트리가 필요하다.
세그먼트 1번을 보면 6300 ~ 6700 이런식으로 할당하는데, 이를 세그먼트 테이블로 관리한다.
base가 시작주소이고 limit는 세그먼트의 크기이다.
limit을 조정하면서 세그먼트의 사이즈를 늘리고 줄일 수 있다.
Hardware support
- 한 세그먼트 테이블에 여러 쌍의 base/limit register
- Segments는 segment #으로 이름이 붙여지고 table에서 index로 사용된다.
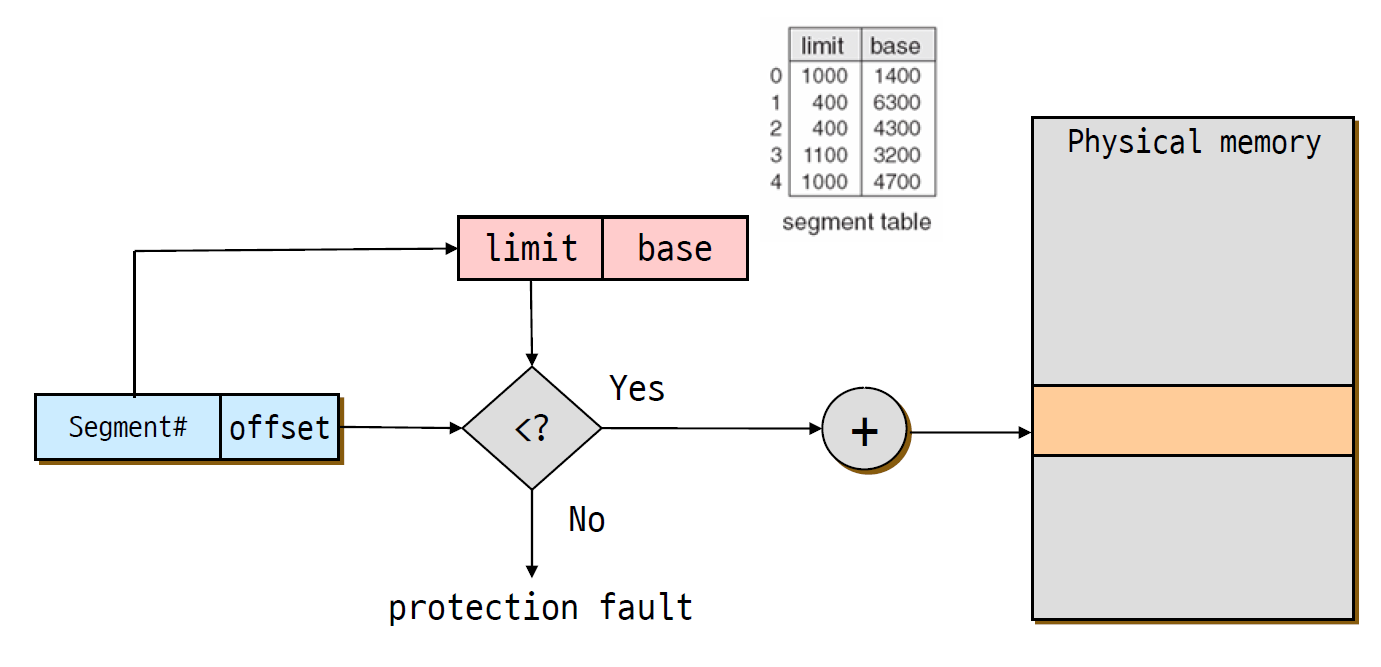
Variable과 비슷하게 limit, base 레지스터가 필요하다. offset을 보고 offset이 limit을 넘어가면 protection fault를 발생시키는 방식으로 작동한다.
세그먼트 장점
- 사이즈가 늘었다 줄었다 변하는 데이터 스트럭쳐를 관리하기 용이하다. 스택같이 계속 변하는 자료 구조도 limit 값만 변경하면 된다.
- 세그먼트를 프로텍션하기 굉장히 좋다.
- 페이징에서 data 영역은 r/w, code는 ex로 세팅할 수 있는데 code + data가 섞인 페이지는 굉장히 곤란하다.
- 그런데 세그먼트 단위는 이런 섞이는 부분이 없어서 좋다. 스와핑도 세그먼트 단위로 하면 좋다.
- 세그먼트 단위로 공유하기 좋다.
- 외부 라이브러리처럼 공유하는 데이터는 base/limit register를 똑같이 주면 공유된다.
세그먼트 단점
- cross-segment address
- 여러 프로세스가 동일한 세그먼트를 공유하려면 해당 세그먼트의 번호가 동일해야 한다. 따라서 프로세스 간 포인터를 사용한 데이터 공유를 어렵게 만든다.
- 따라서 indirect addrssing만 사용해야 한다.
- 무슨 말이냐면, 특정 세그먼트에서 포인터로 얼마만큼 더한 address를 접근하는식으로 포인터를 했다면, 다른 프로세스와 해당 세그먼트를 공유했을 때 그 포인터가 이상한 메모리를 가리킬 수 있다. 어드레스 스페이스가 연속되지 않아서 생기는 문제이다.
- 따라서 세그먼트 내에서만 포인터를 쓸 수 있다.
- external 단편화
- 빈 공간이 조각조각 나있으면 그 부분은 사용할 수 없다.
- 세그먼트 테이블을 프로세스마다 유지, 관리해야 한다. 페이징에 비하면 굉장히 작긴 하다. TLB처럼 하드웨어적 서포터를 받으면 된다.
3. Paging vs Segmentation

- paging은 block size가 정해져있다. 보통 4KB를 쓴다. segmentation은 block size가 변할 수 있다.
- Linear address space : Paging에서는 하나이다. Segmentation에서는 여러개가 된다. 세그먼트끼리 연속된 메모리 주소를 갖지 않기 때문이다.
- Replacement, Disk traffic : Paging은 좀 더 쉽고 페이지 단위로 효율적으로 replace하기 쉽다. Segmentation은 세그먼트마다 사이즈가 다르므로 어렵고 비효율적이다.
- Transparent to the programmers : Paging은 연속적인 주소를 가지므로 프로그래머는 신경쓰지 않아도 된다. Segmentation은 포인터라던지 조심해야할 부분이 있으므로 프로그래머가 신경써야 하는 부분이 존재한다.

- 피지컬한 메모리보다 더 큰 공간을 프로세스가 사용할 수 있을까? : 둘 다 swapping하면서 사용하면 되므로 사용할 수 있다.
- 코드와 데이터가 구별되고 분리되어서 protected 될 수 있을까? : Paging에서는 그러지 못할 가능성이 있다.
- 크기가 변동하는 테이블을 쉽게 조정할 수 있을까? : Segmentation은 base, limit register만 잘 옮겨주면 된다. Paging은 가능은 하다. 페이지를 더 할당해주면 되지만 애초에 그런 목적으로 설계된 기법은 아니기에 불편하다.
- 코드의 share가 쉬운가? : Paging에서는 잘 안될 가능성이 높고 Segmentation은 편하다.
- 왜 해당 기술이 고안되었는가? : Paging은 하나의 긴 연속된 어드레스 스페이스를 제공하기 위해서 고안되었다. Segmentation은 논리적으로 독립된 어드레스 스페이스를 sharing과 protection이 용이하게끔 제공하기 위해 고안되었다.
물론 여기에 나온 개념들이 맞다/틀리다로 항상 나눠질 순 없고, 각 방식의 특징을 잘 기억하고 고안된 목적을 생각하면 구분하기 쉽다!
4. Segmentation with Paging
실제로는 이 두 방식을 hybid 하는 방식을 많이 사용한다.
Segmentation with Paging이라는 기법을 거의 다 사용한다. Segment를 페이지로 쪼개서 관리하는 기법이다. 페이지 사이즈는 CPU 아키텍쳐마다 여러 개의 사이즈를 제공하기도 하고, 하나의 사이즈만 사용하기도 한다.
실제로 동작하는 방식은 어떻게 될까?

기본적으로 Segmentation을 사용한다.
- 코드, 데이터, 힙을 분리해서 사용한다.
- 사이즈 또한 늘렸다 줄였다 하면서 사용한다. (multiple pages)
Segment 하나를 페이지 단위로 쪼개서 사용한다.
- 페이지들을 프레임으로 할당해서 여러 군데로 흩어서 배치하게 된다.
- 이렇게 만들면 demand paging 하듯이 일부는 디스크에 있을 수 있고 일부는 메모리에 있을 수 있다.
- Segments를 메모리로 넣었다가 뺐다가 하지 않고 그냥 페이지만 옮기면 된다.
- external fragmentation이 존재하지 않는다.
- segmentation이 고정된 크기로 분할되기에 존재하지 않는 것이다.
- segmentation table이 필요하고, 각 segmentation마다 page table이 필요하다.

인텔에서 실제로 사용되는 것을 보자.
- logical address에서 selector가 세그먼트 번호가 된다.
- 세그먼트 번호를 가지고 descriptor table를 뒤져보면 세그먼트의 시작 주소(base)와 크기(limit)를 알 수 있다.
- base에 offset을 더해서 linear address를 생성한다.
- linear address는 directory, page, offset으로 구성되어 있다.
- directory는 페이지 디렉토리 주소이다.
- 페이지 디렉토리는 페이지 테이블의 시작 주소를 가리키고 있다.
- directory로 page table에 접근해서 page를 이용해서 frame address를 찾을 수 있다.