2024. 6. 8. 14:29ㆍCS/Operating System
Main Memroy 외부에 존재하는 Secondary storage에 대한 얘기이다.
- Secondary storage에는 instruction을 직접 수행하는 것이 허용되지 않는다. instruction 수행은 CPU만 가능하고 CPU의 instruction의 상대는 메모리로 제한된다.
- Secondary storage에 접근해야 한다면 IO 작업을 통해서만 가능하다.
- 또, 직접적인 read/write는 허용되지 않는다.
Secondary Storage의 특징은 다음과 같다.
- 굉장히 크다.
- 저렴하다.
- 데이터가 지속적으로 저장된다. 전원이 꺼져도 데이터의 손실이 없다. 영속성, 비휘발성이라고도 한다.
HDDs

- 하드디스크는 여러 개의 트랙으로 이루어져 있고, 트랙은 여러 개의 섹션으로 나뉜다.
- N극, S극의 자성으로 섹션에 데이터를 쓰는 방식의 하드디스크가 마그네틱 하드디스크이다.
- 한 섹터에 대략 512 Byte 정도 쓸 수 있는데 끝에 error detection 코드나 parity bit 같은 게 붙기도 한다.
- 하드디스크는 1인치 면적에 굉장히 많은 트랙이 들어갈 수 있으므로 굉장히 세밀하게 구현해야 한다.
- 회전 속도는 7200 rpm 정도로 상당히 빠르다. 한 트랙 안에서 섹션은 빠르게 찾지만 적절한 트랙을 찾는 속도인 seek time은 read는 8.5ms, wirte는 9.5ms 정도로 굉장히 오래 걸린다.
- 내부 캐시 버퍼를 32MB정도 가지고 있다.
- 암과 디스크 사이의 거리도 매우 가깝고 회전 속도는 굉장히 빠른데, 디스크 두께도 굉장히 얇다.
Managing Disk
디스크는 결국 기계적인 장치를 포함하기에 항상 에러의 가능성을 가지고 있다. bad block이 생길 수 있고 seek가 사라질 수 있다.
운영체제 입장에서 디스크는 굉장히 불안하다. 따라서 high-level 소프트웨어 측면에서 뭔가 mess를 숨겨줄 필요가 생긴다. 즉, file, database 등의 레벨에서 디스크의 mess는 신경 쓰지 않아야 한다.
OS는 disk access를 어떻게 다룰까?

- OS는 a.txt같은 logical 파일을 유저 레벨에서 유저 라이브러리를 통해 제공한다. bytes 단위가 된다.
- logical file이 파일 시스템으로 내려오면 disk logical block이 된다. 커널 레벨이고 Blcok 단위로 다룬다.
- blcok layer로 내려오면 디스크의 어떤 섹터에 네가 원하는 정보가 있어 이런 식으로 변환하여 실제 디스크를 다루게 된다. surface, cylinder, secotr 등 피지컬한 disk block을 다루게 되는 것이다.
실제로 디스크에 엑세스하려면 OS는 표면, 실린더, 트랙, 섹터, transfer size 이런 정보를 다 포함해서 명령을 내려야 한다. file system과 block layer를 거쳐서 위의 정보들을 보내야 한다는 것이다.
요즘의 디스크들은 high-level 인터페이스를 지원한다.
디스크 자체가 이런 저런 좋은 기능들을 제공하고 SCSI, SATA 모두 섹터가 아니라 logical 블락 번호로 디스크를 보여준다. 디스크에 섹터가 몇 개 있는지, 트랙이 몇 개 있는지 이런 건 내부에서 숨기고 외부에 블락 0~N-1번까지 있다고만 알려준다.
block 번호만 주면 디스크가 알아서 실린더 번호, 트랙 번호로 변환하므로 OS는 블락 번호와 연산만 넘겨주면 된다.
디스크의 성능은 seek, rotation, transfer에 달려있다. seek은 매우 오래 걸린다. rotation은 내가 원하는 섹터까지 회전해서 움직이는건데 그렇게 빠른 편은 아니다. transfer는 빠르다.

즉, seek은 트랙을 맞추는 시간, rotation은 디스크를 회전시켜서 섹션을 맞추는 시간, transfer은 읽어들이는 시간이다.
Disk Scheduling
seek time이 굉장히 크다보니 사람들은 disk scheduling을 생각하게 된다.
디스크는 많은 요청이 들어오면 굉장히 바쁠 것이다.
따라서 디스크 내부에 큐를 가지고 운영체제가 block device를 디스크에 요청하게 되면 큐에 달아두고 연산을 다 수행했다면 운영체제에게 알려주는 방식으로 작동하게 된다.
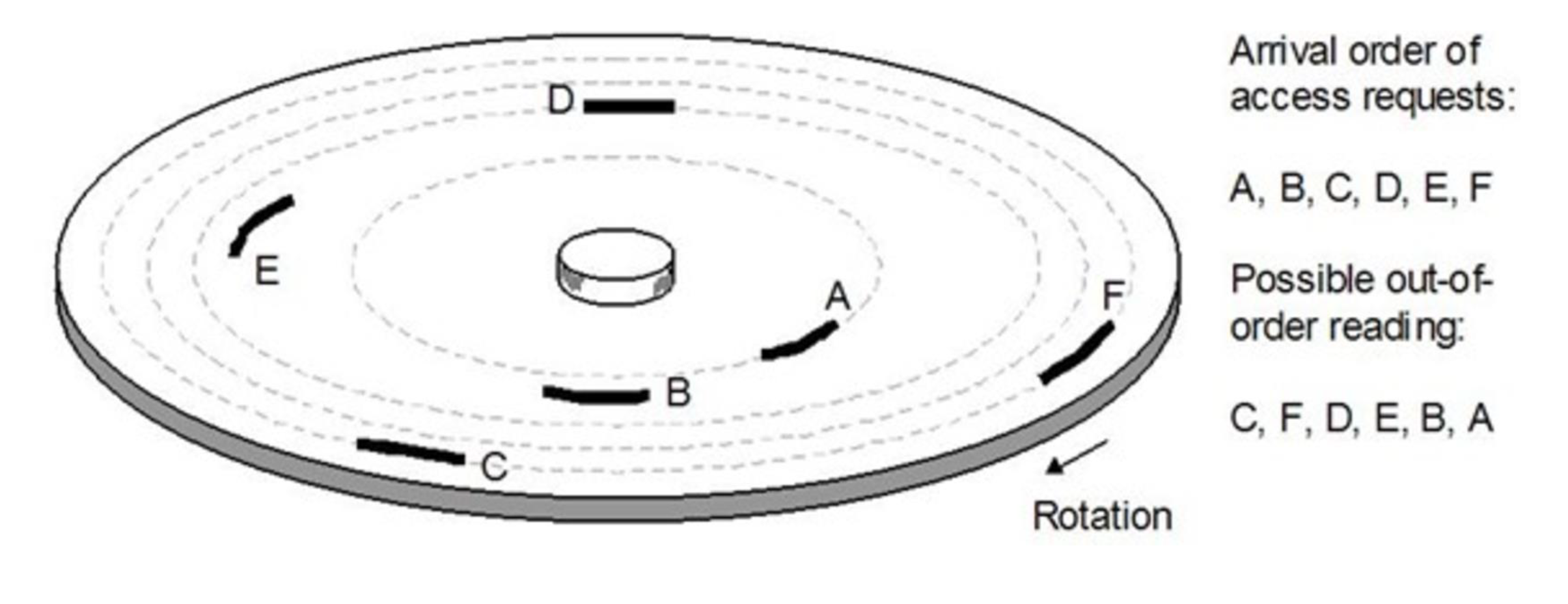
이 과정에서 스케줄링 문제가 생긴다. 큐에 존재하는 job들을 어떤 순서로 접근하는 게 가장 좋은가이다.
A B C D E F로 들어왔다면 FIFO로 처리하는게 합리적이긴 한데 seek 횟수가 너무 크다.
순서를 C F D E B A로 바꾼다면 seek이 왔다갔다하지는 않고 가장 바깥에서 안쪽으로 훑으면 되므로 seek 횟수가 줄어든다. 즉, 스케줄링에 따라 seek time이 바뀌게 된다.
FCFS(FIFO)
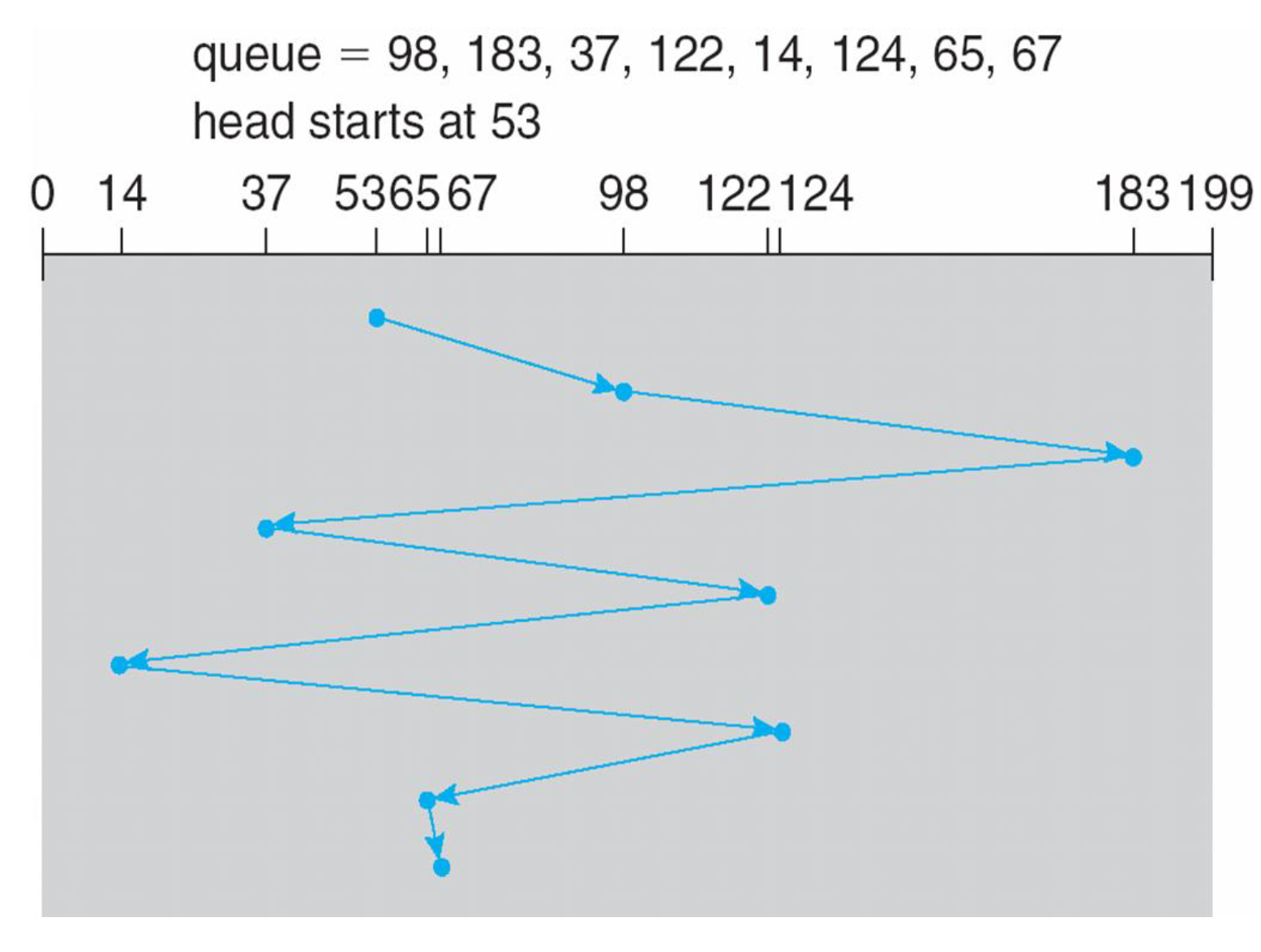
- 꽤 합리적이다.
- request가 굉장히 많아지면 waiting time이 늘어질 수 있다.
- 왔다 갔다 왔다 갔다 하면서 seek가 일어난다.
SSTF : Shortest Seek Time First

- seek time이 가장 짧은걸 먼저 골라서 액세스 하는 방식이다.
- 헤드가 53에서 가장 먼저 시작했다면 그다음 가장 가까운 65 67 37 14 … 이런 방식이다.
- arm의 움직임을 최소화시키는 알고리즘이다. 그럼 seek time이 가장 적어지고 따라서 io 성능이 좋아진다.
하지만 두 가지 문제가 생긴다.
- 가운데에 배치되어 있는 blocks가 선호된다. 선호되는 block이 있어서는 안 된다.
- starvation의 문제도 생길 수 있다.
SCAN (엘리베이터 알고리즘)

- 마치 엘리베이터가 동작하듯이 한 방향으로 쭉 가면서 다 처리하고 끝에 도달하면 반대 방향으로 쭉 다 이동하면서 다 처리하는 방식이다.
- starvation은 존재하지 않지만 waiting time이 uniform 하지 않다는 문제가 있다.
- 데이터가 어디에 존재하고 엘리베이터 방향이 어떠냐에 따라 waiting time이 너무 길어질 수 있다.
Circular SCAN
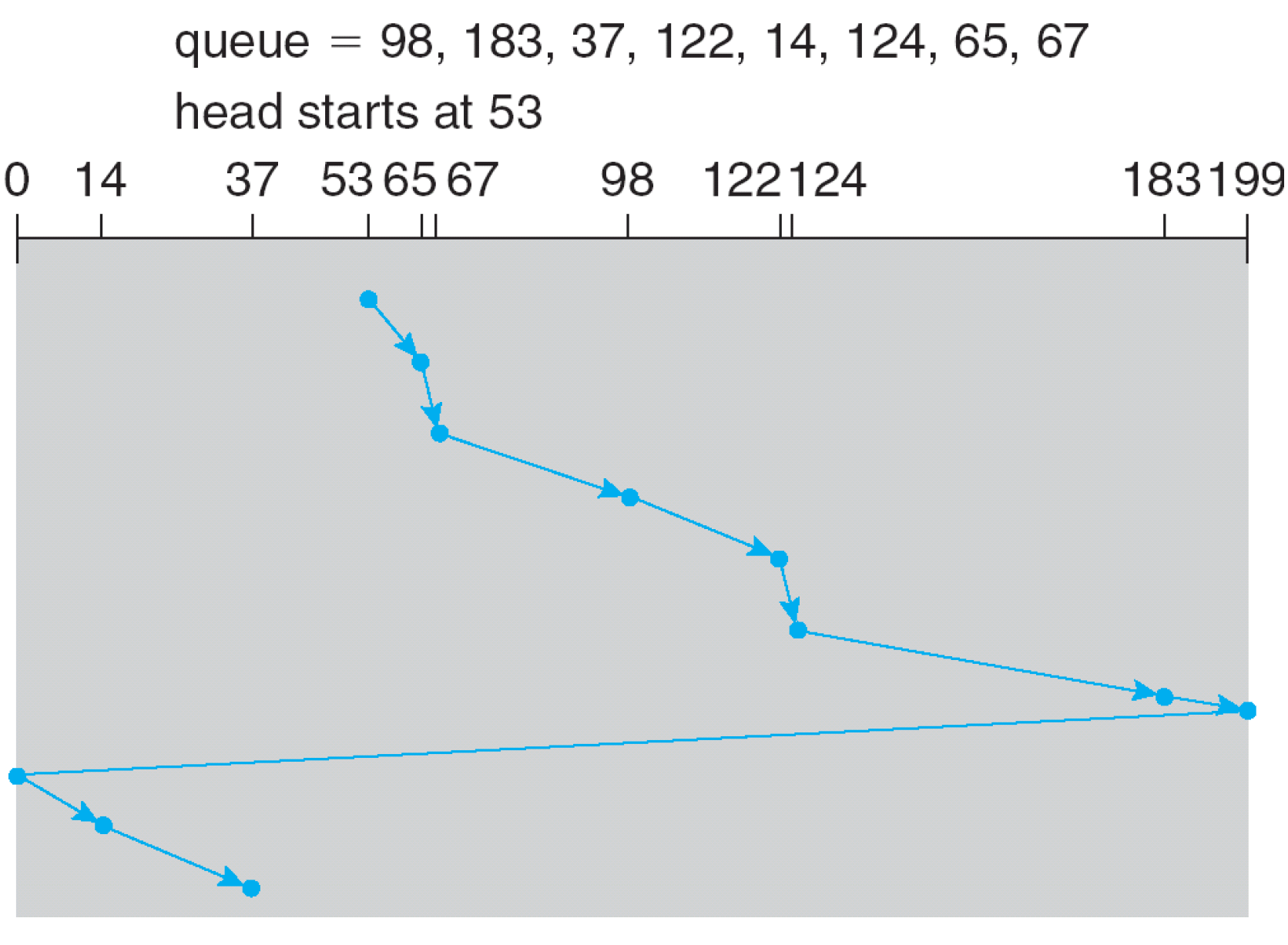
- scan인데 한 방향으로만 처리하겠다는 것이다.
- 53에서 오른쪽으로 쭉 처리하고 끝까지 도달하면 다시 0으로 와서 오른쪽으로 쭉 가면서 처리하는 방식이다.
- waiting time이 조금 더 uniform 해진다.
LOOK/C-LOOK
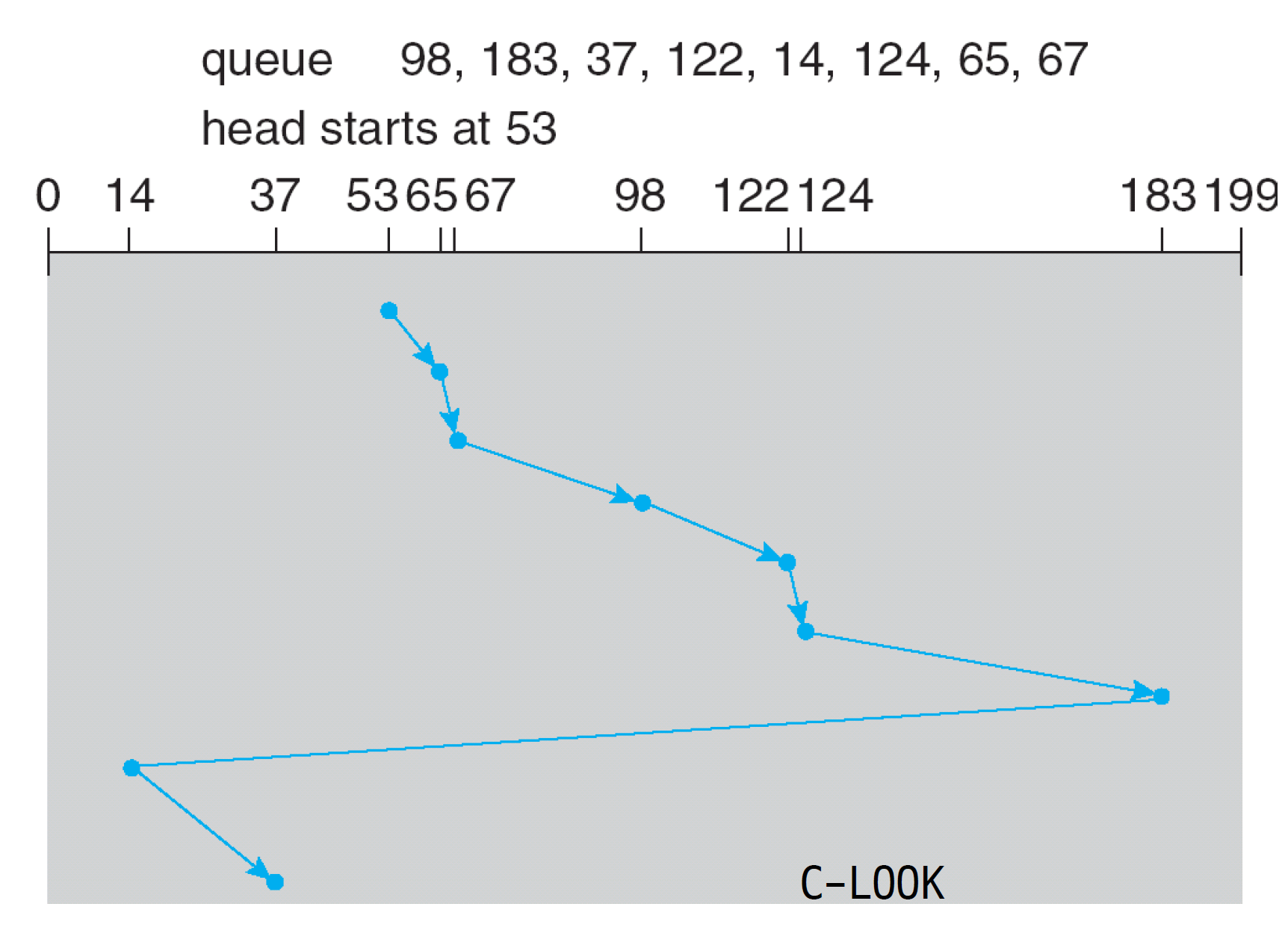
- arm이 final request가 존재하는 곳까지만 간다.
- 끝을 찍지 않고 183에서 반대 방향으로 진행(LOOK)하거나 다음 최솟값 요청으로 가는 것(C-LOOK)이다.
- 조금 더 빠를 것이다.
어떤 스케줄링 알고리즘이 가장 좋을까?
- SSTF는 자연스럽고 seek time을 최소화시킬 수 있다.
- SCAN, C-SCAN는 디스크에 가해지는 load가 클 때 성능이 좋다.
- SSTF, LOOK, C-LOOK이 합리적이고 디폴트 알고리즘으로 많이 사용한다.
- 성능은 request의 수와 타입에 달려있다.
- 사실 더 중요한 건 파일을 어떻게 디스크에 배치했는지에 따라 성능이 굉장히 달라지게 된다. 예를 들어 a.txt를 4개의 섹터에 배치해야 한다면 당연히 한 트랙에 4개 섹터로 연달아서 배치하는 게 좋다.
현대의 디스크는 최적화된 스케줄링 알고리즘은 디스크 알아서 한다.
- 디스크 내부에 작은 CPU와 메모리를 가지고 있어서 알아서 알고리즘을 돌린다.
- 또 컨트롤러 안에 작은 CPU와 메모리가 있어서 컨트롤러 만드는 회사가 작성한 프로그램을 실행한다.
- read-ahead라는 기능도 존재한다. 내가 읽으려는 데이터의 앞에 있는 것도 미리 다 읽어둬서 버퍼에 기록하는 것이다.
- 자주 액세스되는 블락이라면 dram에 캐싱하는 방법도 있다.
- Command queuing, request reordering 같이 자기가 알아서 최적화하는 기능도 있다.
- bad block, track을 remapping 한다거나 그런 기능도 있다.
결론은 현대의 OS는 Secondary Storage에 큰 신경을 쓰지 않는다는 것이다.
I/O Scheduler
그럼에도 아직 I/O Scheduler가 들어있긴 하다.
I/O Scheduler의 목표
- request의 수를 줄이기 위해 merging request
- seek time을 줄이기 위해 request reordering, sorting
- prevent starvation
- fairness
- QoS(내가 IO를 요청하면 1ms 이내로 응답을 받아야 한다 등 quality of service)