파일 시스템 개요
유저 관점에서 파일 시스템은 다음과 같다.
- 파일을 어떻게 이름 붙이지?
- 권한은 어떻게 설정하지?
- 디렉터리 트리어떻게 구성하지?
시스템 입장에서는 다음과 같다.
- 파일과 디렉터리를 어떻게 디스크 블락에 배치해서 저장해야 하지?
- 디스크의 공간이 사용자 빈공간 이런 게 있을 텐데 이걸 효율적으로 안정적으로 잘 관리해야 한다.
디스크에는 OS가 사용하는 첫 번째 블락이 반드시 존재해야 한다. OS가 쓰는 것이다.
하나의 디스크를 파티션으로 나누어 관리할 수 있고 보통 아래와 같은 구조를 가진다.

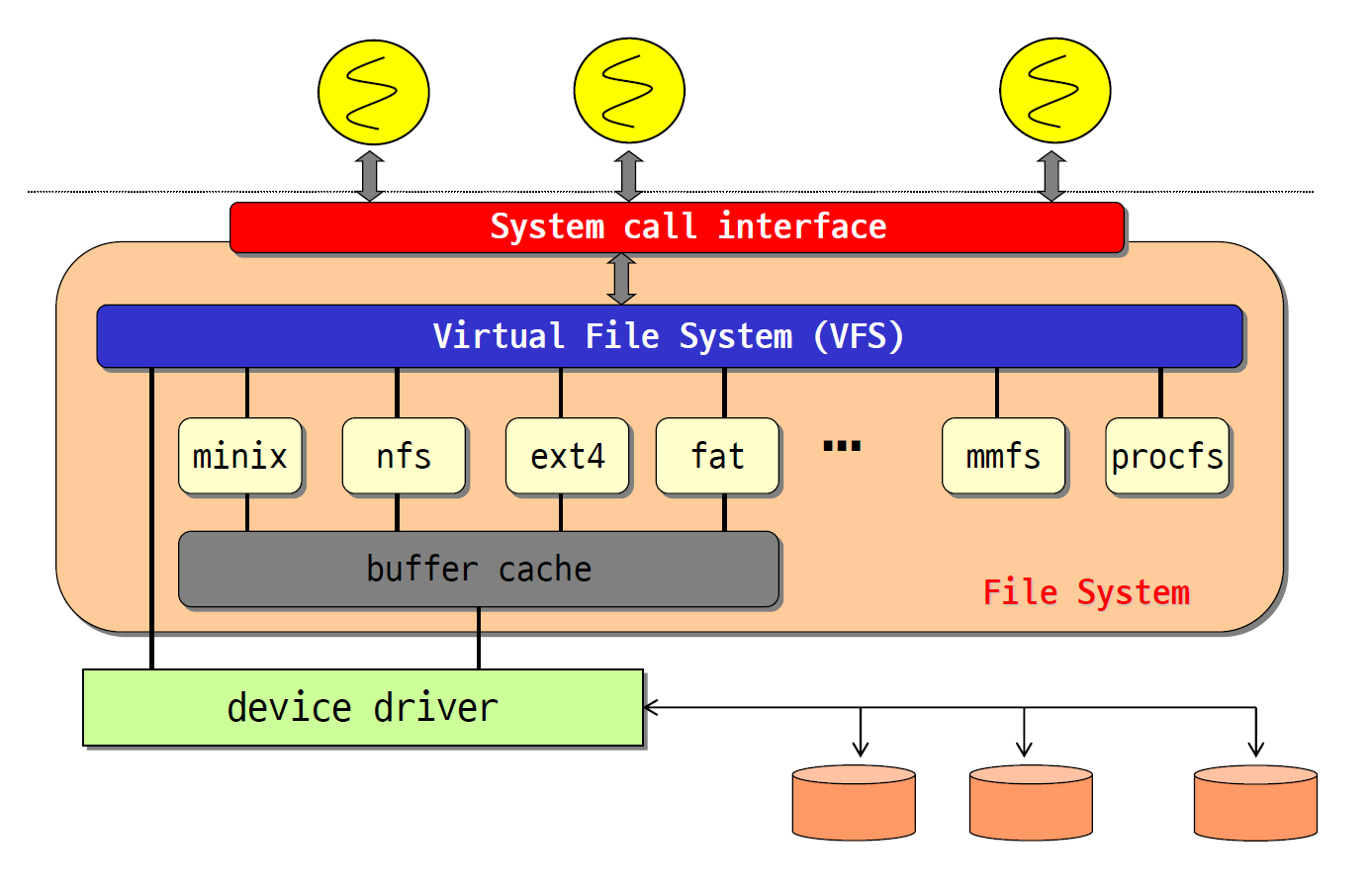
하나의 운영체제가 여러 파일 시스템과 여러 스토리지를 지원해야 하기에 하나의 통합된 VFS가 있다.
성능상의 문제로 버퍼 캐시가 있고 그 밑에 디바이스 드라이버가 동작한다.
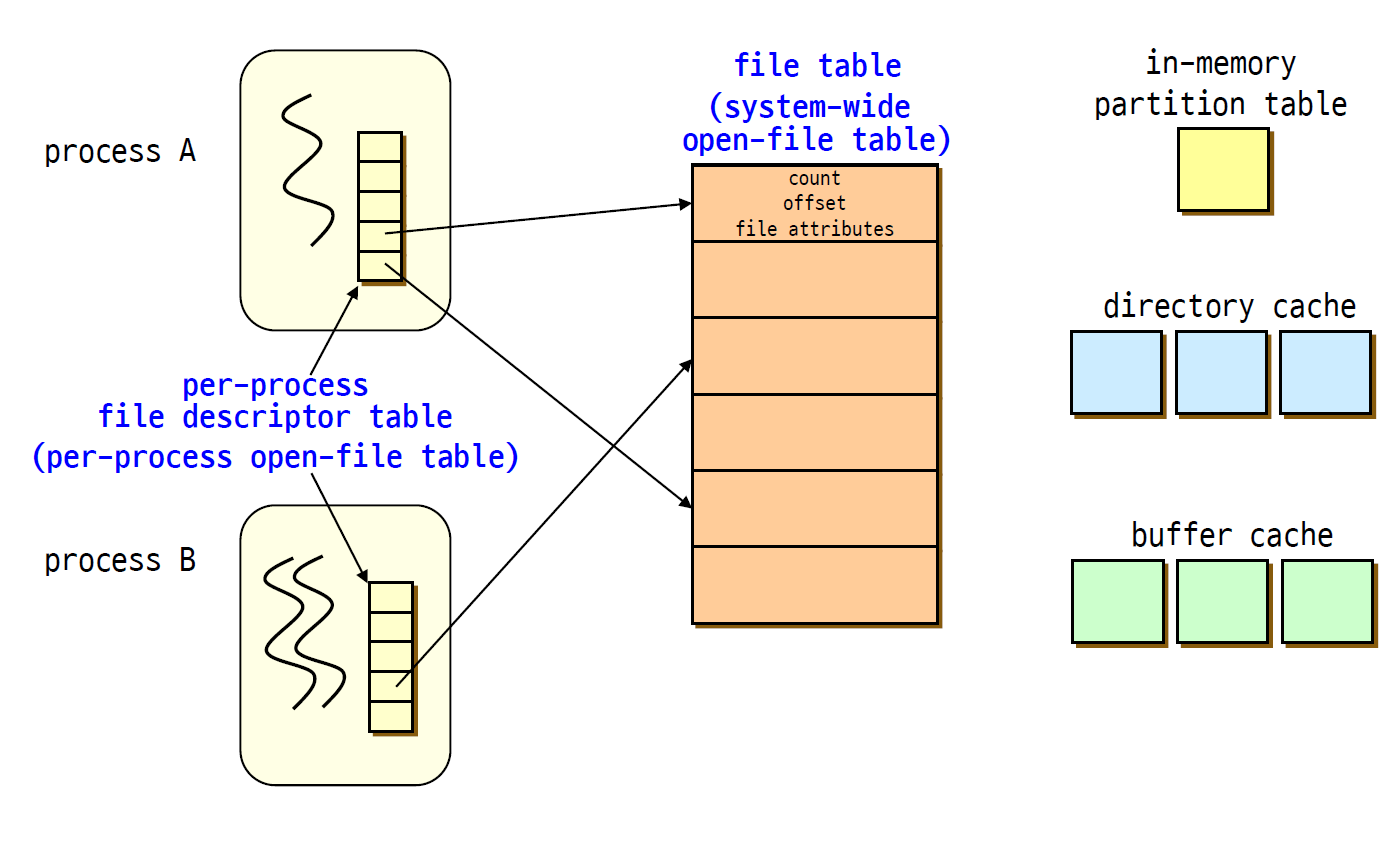
메모리 안에서는 PCB를 따로 가지는 것 처럼 프로세스마다 file descriptor table이 있다.
OS는 descripor table을 보면서 파일이 뭐가 열려있고 해당 파일은 누가 사용한다는 정보를 확인한다.
그들을 위해서 디렉터리 캐시, 버퍼 캐시가 있어서 캐싱할 수 있다.
VFS : virtual file system
- 말 그대로 가상의 파일 시스템이다.
- 모든 파일 시스템에게 하나의 포맷을 제공하기 위해서 제공되는 시스템이다.
- 내가 오픈하고 싶은건 a.txt이지 a.txt가 ext4에 저장되어 있는지 nfs에 저장되어 있는지 그런 건 알고 싶지 않다. 따라서 a.txt를 open system call을 호출하면 system call interface가 받고 그 명령을 VFS로 보내고 마운트 포인터를 보고 해당 파일의 위치를 확인한 뒤 디스크에서 읽게 된다.
리눅스에서 사용되는 VFS file model을 알아보자.
- superblock : 처음에 마운팅 되면 읽어진다. 파일 시스템에 관한 정보를 담고 있다.
- dentry : 디렉터리와 파일의 연결을 담고 있다. 디렉터리를 오픈하면 dentry object를 사용하는 것이다.
- inode : 특정 파일에 대한 일반적인 정보를 담고 있다. 파일을 오픈하면 inode object를 사용하는 것이다.
- file : 열린 파일과 프로세스 간의 상호작용에 관한 정보를 담고 있다.
Directory Implementation
a디렉터리에 b, c, d가 있으면 해당 디렉터리는 파일 이름과 파일 속성을 가지고 있다. 어떻게 metadata를 저장하는지는 주로 세 가지 방식이 존재한다.
directory entry

- fixed length entries
- 엔트리 수를 100, 파일 이름 200 이런 식으로 설계할 수 있다.
separate data structure

- linked list처럼 테이블을 늘리면서 만들 수 있다.
- search 하는 문제가 있을 수 있다.
- b tree나 해시 테이블을 사용하면 searc 타임을 줄일 수 있다.
- hash의 장단점을 그대로 가진다. 해시 펑션에 의존적이라던지 충돌이 나면 노드를 쭉 달아야 하는 등의 문제이다.
hybird

한 디렉터리에 많은 파일이 들어가야 한다면 hash table이 유리하다. 일반적으로 linear list를 많이 사용하긴 하는데 선택의 문제이다.
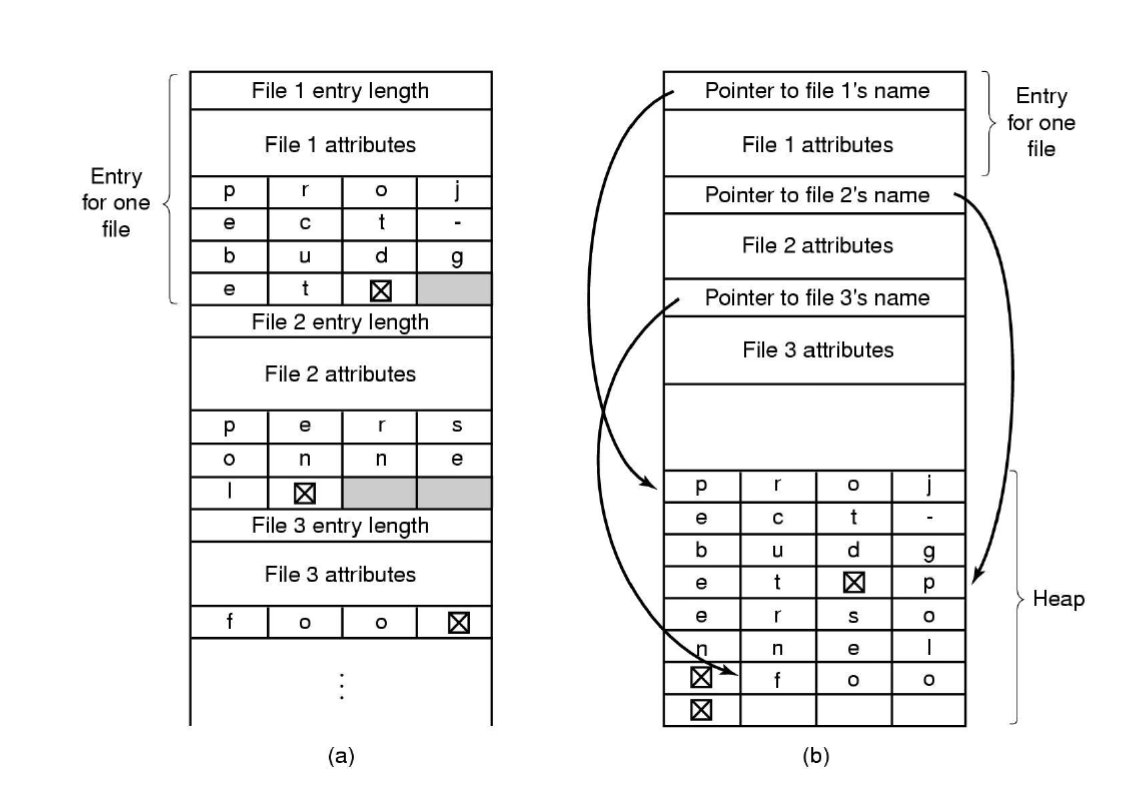
메타데이터의 배치도 고민이 된다. 디렉터리 엔트리에 같이 저장할 수도 있고 분리시킬 수도 있다. 분리시키는 경우에는 파일 이름과 linked list로 어느 block에 있는지 링크해 둘 수 있다. 하이브리드도 존재한다.
자주 쓰이는 건 디렉터리 엔트리에 같이 저장하고 자주 쓰이지 않는 건 다른 block에 저장해서 링크해 놓는 방식이다.
(a) 방식은 디렉터리에 넣는 방식이다. 해당 방식은 사이즈가 고정되어서 파일의 이름의 길이가 제한된다. 따라서 파일의 이름을 길게 만들고 싶으면 엔트리 하나에 대해 파일의 이름 길이를 정해놓고 파일마다 저장하기 할 수 있다.
(b) 방식은 파일의 이름은 Heap에 모아두고 포인터로 링크해두는 방식이다. 엔트리를 고정 크기로 구성할 수 있다. (b) 방식이 좀 더 파일의 이름을 길게 만들 수 있다.
Allocation
디스크 block에 대한 allocation의 문제이다. 하나의 파일은 <file name, metadata, file data>로 구성된다. 이걸 어떻게 block에 배치할까?
Contiguous allocation

- 파일별로 필요한 길이만큼 연속된 blcok으로 할당한다.
- 디렉터리 엔트리에서 파일의 이름과 시작 blcok 번호와 길이만 알면 돼서 좋다.
- 심플해서 편하고 디스크를 생각하면 같은 트랙에 배치되어 있을 확률이 높아서 seek time이 굉장히 줄어들 든다.
- 단점은 dynamic storage allocation : first / best fit 같은 방법이 필요하다. 파일의 사이즈가 변해서 예측하기가 굉장히 힘들다.
- 외부 단편화 문제가 생긴다.
- compaction 시켜도 되지만 엄청나게 오래 걸린다.
- 다만 CD-ROM인 경우 좋다. 파일 사이즈가 변하지 않아서 좋은 것이다.
좀 더 개선된 방법은 연속된 청크를 만들어서 청크 단위로 배치하는 것이다.
좀 더 심플하고 metadata 또한 <name, starting dist block, chunk length, link to the extent>와 같이 구성할 수 있어서 간단하다.
하지만 internal, external 단편화 문제를 둘 다 가진다.
Linked allocation
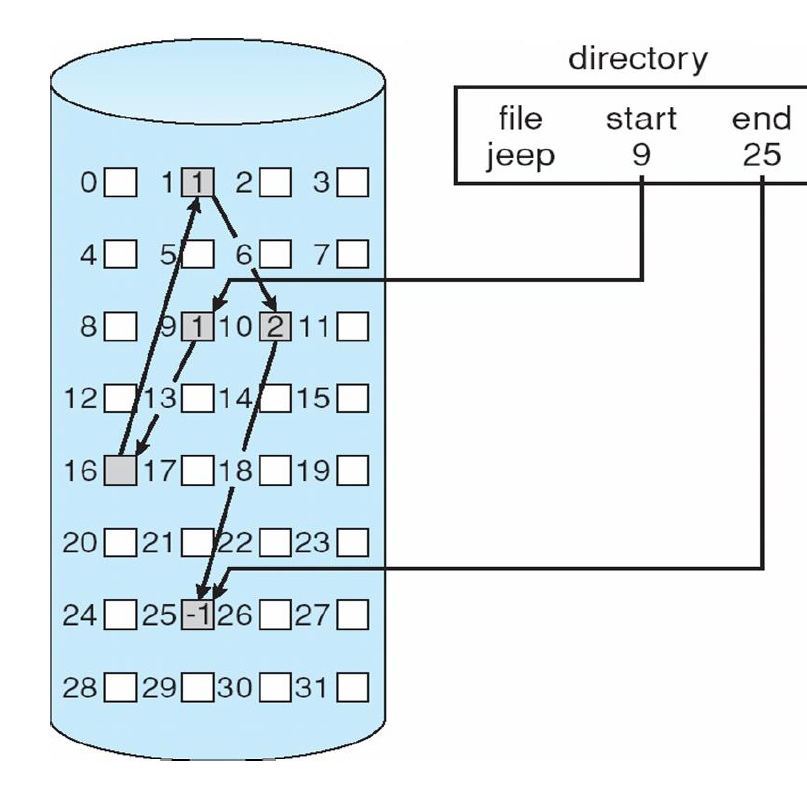
- 시작이 9번 block이라면 9번 먼저 가고 조그마한 포인터를 보고 계속 가다가 끝이 어딘지 보고 끝난다.
- 디렉터리 엔트리에는 start, end 포인터만 있으면 된다.
- 연속적으로 할당하지 않아도 돼서 external 단편화는 없다.
- 블락만 알면 된다. free block만 있으면 파일 사이즈를 계속 늘리 수 있다.
- 단점은 트랙을 왔다 갔다 해야 하기에 seek overhead가 커진다. SSD를 쓰면 오버헤드가 적긴 하다.
- 포인터를 유지하는 스페이스 오버헤드가 존재한다. 몇 바이트 정도는 링크를 위한 block 번호를 적어야 한다.
- dead block이 나서 포인터가 죽어버리면 파일 전체를 읽을 수 없다. 불안정하다는 것이다.
청크처럼 클러스터로 묶어서 사용하는 개선된 Linked allocation 방식도 존재한다.
클러스터 단위로 blcok을 묶고, 클러스터로 파일을 배치하는 방식이다.
logical to physical block 매핑이 좀 더 쉬워진다.
disk seeks가 줄어서 디스크 throughput도 좀 더 좋아질 것이다.
포인터에 대한 오버헤드도 더 줄 것이다. 한 클러스터에 여러 blcok이 있는데 한 클러스에만 포인터가 있으면 되기 때문이다.
내부 단편화 분제가 있고 불안정성은 여전하다.
Linked allocation using a FAT

- 디렉터리 엔트리에 start block을 적어놓는다. start block에 file allocation tabe, FAT의 start block가 link 되어 있고 FAT를 따라서 다음 blcok을 찾는다.
- 효율적이고 FAT이 중요한 역할을 한다.
- FAT이 캐싱만 잘 되어있으면 seek를 꽤나 줄일 수 있다.
- 메모리에 FAT을 올려야 하므로 메모리 부담이 존재한다.
- USB에서 기본으로 사용한다.
Indexed allocation
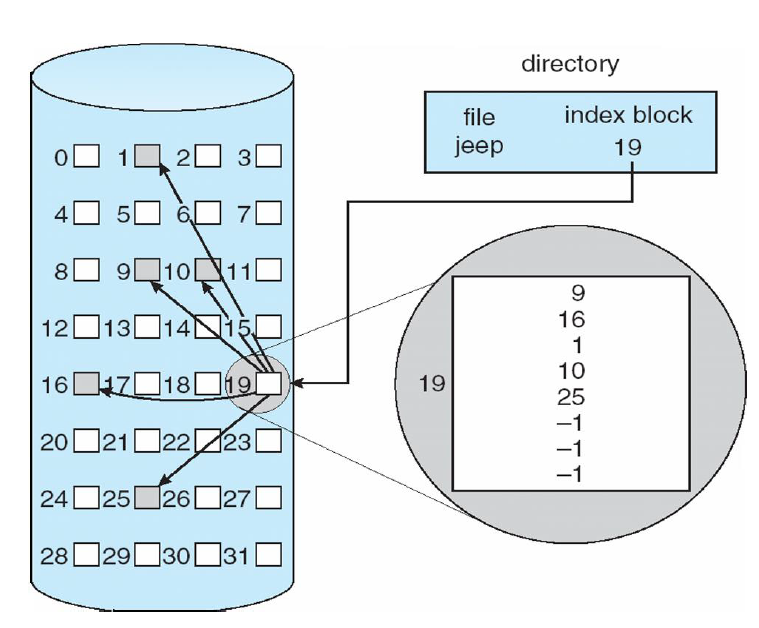
- 요즘 대부분 사용한다.
- 디렉터리 엔트리에 index block이 하나 적혀있다.
- index block(inode)에 들어가면 내가 액세스 해야 하는 블록이 순서대로 적혀있다.
- index block를 보면 크기가 고정되어 있어서 남는 건 -1로 채운다.
- 문제는 고정된 크기를 넘어가면 어떻게 될까? 문제가 있다.
- 각 파일은 각자의 index block을 가진다.
- 장점은 direct access를 지원한다는 것이다. index로 특정한 블록에 바로바로 접근할 수 있다.
- index block을 메모리에 올려서 캐싱하면 정말 빠르다.
- 단점은 index block을 위한 메모리 오버헤드가 존재한다.
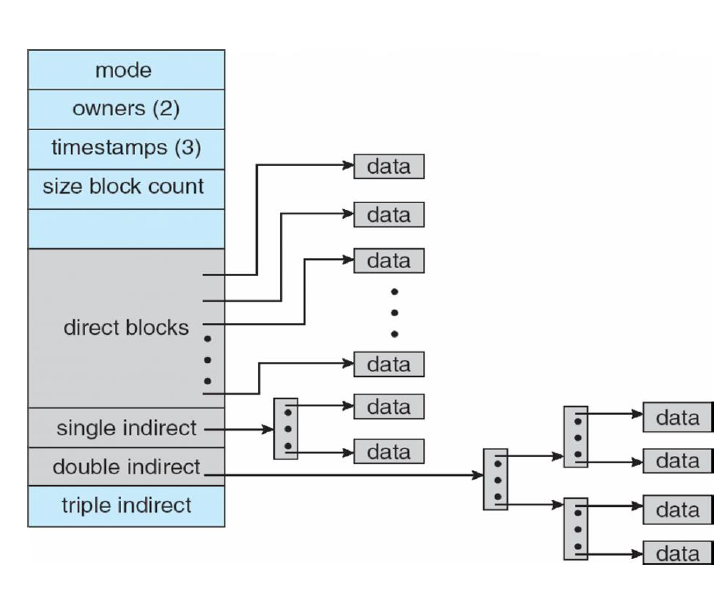
리눅스의 inode는 멀티 레벨로 만든다.
direct block을 위한 blcok을 정해놓고 바로 접근할 수 있다. dircect block으로 부족하면 single indirect가 있어서 거기에 접근하면 direct block이 존재한다. double에 가면 single이 또 있다.
이렇게 하면 굉장히 큰 파일까지 커버할 수 있다. 대부분은 direct block에서 끝나고 아무리 커도 얼마든지 확장할 수는 있지만 그에 따라 direct block이 좀 늘어날 수 있다.
빈 공간 관리
bitmap으로 관리할 수 있다.
- block 별로 비트로 매핑하는 것이다.
- bit mask를 한 번하면 비었는지 아닌지 모든 블락에 대해 알 수 있다.
- blcok 하나당 한 비트라 그렇게 큰 사이즈는 아니다. 심플하고 효과적으로 빈 블락을 찾아낼 수 있다.

linked list로 빈 공간을 달 수도 있다.
- first free block의 포인터만 가지고 있으면 된다.
- 중간에 존재하는 free blcok 쓴다면 링크만 바꿔주면 되고 새로운 블락이 생겨도 끝에 달아주면 돼서 오버헤드가 적다.
- dead block이 나면 링크가 다 깨지는 문제가 있다.
성능
blcok size와 성능은 Trade-off 관계이다.

- blcok이 커지면 seek가 적게 일어나서 성능이 좋아진다.
- 대신 block의 사이즈가 어느 수준 이상 커지면 디스크 활용도가 많이 떨어진다.
- 단편화가 많이 일어나는 것이다. 보통은 4K를 쓴다.
버퍼캐시(페이지캐시)
- 파일을 read, write 하는 애플리케이션은 locality가 높다. 특정 파일 block을 반복해서 read, write 하는 경향이 높다는 뜻이다.
- 따라서 자주 사용되는 file blockd을 메모리에 캐시 하면 좋을 것 같다.
- 운영체제의 버퍼 캐시는 시스템 전체에서 사용되며, 모든 프로세스가 공유한다. 디스크를 캐싱하고 있는 메모리이다.
- 버퍼 캐시에서 읽는 것은 디스크를 메모리처럼 작동하게 만든다.
- 심지어 아주 작은 캐시도 매우 효과적이다.
- 그런데 이 버퍼 캐시는 프로세스와 같이 사용하기에 Virtual Memory와 경쟁해야 한다.
- 버퍼 캐시 교체 알고리즘도 필요하다.
Read ahead
- 디스크가 필요한 파일을 미리 읽는데, 파일 시스템도 디스크를 미리 읽어달라고 OS에 요청할 수 있다.
- block 하나를 읽는 동안 다음 block을 미리 버퍼캐시에 올려놓으면 computing과 IO가 동시에 일어나서 성능이 좋아진다.
- 예를 들어 파일 전체 중 얼마를 읽고 있다면 메모리에 다음 block 올려두고 다음 block 읽으려고 하면 히트가 났으므로 그 두 배만큼의 block을 미리 올려두게끔 동작한다.
- sequentially accessed files에게 매우 효과적이다. 파일을 allocation 할 때 연속되게 배치하는 게 중요하다는 뜻이다.
- 이를 위해서 주기적으로 데이터 블락들의 배치를 바꾸기도 한다.