https://www.youtube.com/watch?v=vT1JzLTH4G4&list=PLC1qU-LWwrF64f4QKQT-Vg5Wr4qEE1Zxk&index=3
스탠포드 대학교의 유명한 컴퓨터 비전 강의를 보고 정리한 글입니다.
https://www.youtube.com/playlist?list=PLetSlH8YjIfXMONyPC1t3uuDlc1Mc5F1A
CS231n 강의와 서울대학교 DSBA 연구실의 강의를 참고하여 공부한 부분을 정리하였습니다.
이번 강의를 들으면서 처음 AI 공부를 시작했고, 그만큼 틀린 부분 해석이 모호한 부분이 있을 수 있습니다.
3. Loss Function & Optimization
1. Review
이미지 인식에 있어서 고양이를 찍는 방향, 빛의 세기, 고양이가 고양이 답지 못한 포즈를 취하는 경우, 소파에 고양이가 숨은 경우, 배경과 고양이를 구별하기 힘든 경우, 고양이 안에서도 다양한 종이 있는 경우 인식하기 힘들다는 문제점이 있었다.
Data-Driven Classifier를 살펴보았는데 K-NN Algorithm과 일반화 성능을 높이기 위한 K-fold Algorithm을 살펴보았고 검증 결과를 이용하여 최적의 K를 선택하는 과정도 알아보았다.
Linear Classifier, Score Function을 알아보았는데 이미지 픽셀을 x로 표현하고 우리가 학습해야할 W가 랜덤한 값의 행렬을 가진다면 Score Function은, f = Wx + b로 표현할 수 있다. 이 과정을 통해 10개의 class score를 구할 수 있었다.
우리가 작성한 score function이 얼마나 데이터를 잘 표현하는가를 평가하는 loss fucntion을 정의하고, loss function을 최소화하는 최적화 방법에 대해 배워보자.
2. Loss Function
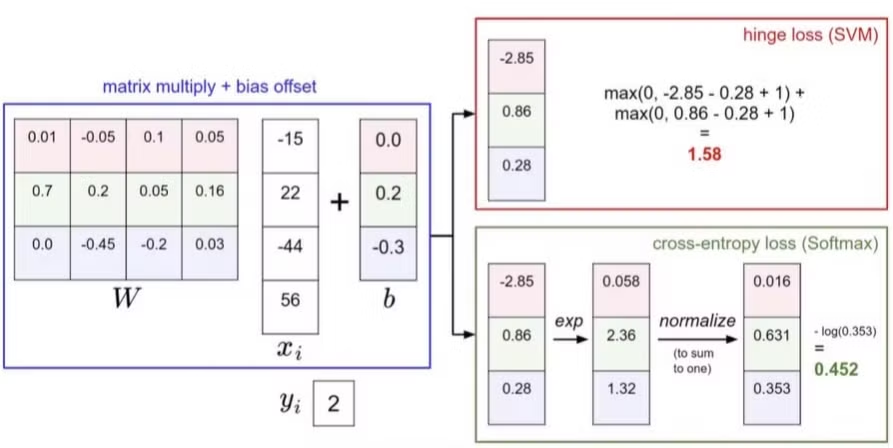
이번 강의에서 사용할 데이터는 3개의 학습 데이터, 3개의 클래스로 구성되어 있고 임의의 W로 계산한 Score는 다음과 같다고 가정한다.

Multiclass SVM loss
학습 데이터 (xᵢ, yᵢ) 에 대해 xᵢ는 이미지가 되고, yᵢ는 정수 값의 범주 레이블이다.
scores vector : s = f(xᵢ, W), W는 학습하고자하는 가중치이다.
이때 SVM loss는 다음과 같이 정의할 수 있다.여기서 j는 정답이 아닌 case에 대해 하나씩 반복하게 된다. sⱼ 는 오답일 때의 score, s_yi는 정답일 때의 score이다. + 1은 SVM의 margin 값이 된다.
$$ L_i = \sum_{j \neq y_i}^{} max(0, s_j - s_{yi} + 1) $$
여기서 j는 정답이 아닌 case에 대해 하나씩 반복하게 된다. sⱼ 는 오답일 때의 score, s_yi는 정답일 때의 score이다. + 1은 SVM의 margin 값이 된다.
- 추정 값과 정답 사이의 margin을 반영하고 이 값과 0을 비교하면서 더 큰 값을 해당 값의 loss로 정의한다. margin 보다 작은 score 크기 변화는 loss에 영향을 주지 않는다.
- 이게 무슨말이냐면 정답 클래스의 점수와 오답 클래스의 점수 차이가 최소 margin 값 이상 나야 한다는 것이다. 만약 s_j - s_yi ≤ -1이면, 즉 오답 클래스의 점수가 정답 클래스보다 1 이상 낮다면 loss는 0이 된다. 이 경우 이미 충분히 오답 클래스와 정답 클래스의 score 차이가 많이 난다고 판단하여 더 이상 학습할 필요가 없다는 의미이다.
- 예를 들어, s_j - s_yi 가 -0.2라면, margin 값인 1 이상 차이가 나지 않는다. 아직 오답 클래스가 정답 클래스와 충분히 구분되지 않으므로 학습을 계속해야 한다는 신호로 loss가 0.8이 된다.
- 전체 training loss는 모든 학습 데이터에서 발생한 loss의 평균값이다.
- $$ L = \frac 1 N \sum_{i=1}^{N}L_i $$
Multiclass SVM loss 예제

이 데이터의 SVM Loss를 계산해보자.
고양이 사진에 대해 W를 내적한 score 값은 [3.2, 5.1, -1.7]이다.
고양이 사진에 대해 L_i를 계산해보자.
$$ L_i = max(0, 5.1 - 3.2 + 1) + max(0, -1.7 - 3.2 + 1) $$
$$ = max(0, 2.9) + max(0, -3.9) = 2.9 $$
똑같은 방식으로 다른 사진에도 적용을 해보면 차례대로 loss 값은 [2.9, 0, 10.9]가 된다. 각 이미지에 대한 loss 값을 구했으므로 전체 모델에 대한 loss는 다음과 같다.
$$ L = (2.9 + 0 + 10.9)/3 = 4.6 $$
이정도로 SVM Loss의 기초적인 학습은 마무리 하고, 추가적인 이해를 돕기 위한 질문이 몇 가지 있다.
- what if the sum was instead over all classes? (including j = y_i)
- j = y_i, 즉 정답 케이스인 경우는 L_i를 계산할 때 더해주지 않았는데 만약 정답 케이스까지 더해준다면 어떻게 될까?
- 모든 loss에 1씩 추가가 되기에 더해주면 안된다.
- what if we used a mean instead of a sum here?
- sum 대신 mean(평균)을 사용하면 어떻게 될까?
- mean으로 설정해도 무관하다. 결국에는 W의 loss를 최소화하기만 하면 된다.
- what if we used
- 이렇게 제곱을 하는 방식이 특정 경우에 더 좋은 성능을 보이기도 한다.
- $$ L_i = \sum_{j \neq y_i} max(0, s_j - s_{yi} + 1)^2 $$
- what is the min/max possible loss?
- 정답에 가까워 질수록 0에 가깝고, max는 무한대로 늘어날 수 있다.
- usually at initialization W are small numbers, so all s ~= 0 What is the loss?
- W가 아주 작은 값을 가지면 score가 0에 근접하게 되는데, 이 경우 loss 값은 어떻게 될까?
- 스코어가 0으로 가깝게 되면 각각 클래스에 대해 loss 값이 1이 된다. 그런데 우리는 정답은 세지 않으므로 1의 loss 값의 개수는 클래스의 개수 - 1이 된다.
실제 구현을 해보자.
import numpy as np
def L_i_vectorized(x, y, W):
(" A faster half-vectorized implementation. \\n"
"half-vectorized refers to the fact that for a single example the implementation contains no for loops,\\n"
"but there is still one loop over the examples. (outside this function)")
delta = 1.0 # margin
scores = W.dot(x) # compute the margins for all classes in one vector operation
margins = np.maximum(0, scores - scores[y] + delta)
# on y-th position scores[y] - scores[y] canceled and gave delta.
# We want to ignore the y-th position and only consider margin on max wrong class
margins[y] = 0
loss_i = np.sum(margins)
return loss_i
주어진 가중치 W, 입력 벡터 x, 정답 레이블 y를 사용해 SVM loss를 빠르게 계산할 수 있는 방식이다. 주석을 보면, 현재 코드의 L_i_vectorized() 함수는 하나의 y에 대해 SVM loss를 계산하는 것이다. 실제로 여러 개의 예제에 대해 총합 loss를 계산하려면 각 예제에 대해 for 루프를 돌게 된다.
- delta가 margin이 되고 SVM의 하이퍼 파라미터이다.
- scores = W.dot(x) : 가중치 행렬 W와 입력 벡터 x 간의 행렬 곱이다. 이를 통해 모든 클래스에 대한 점수가 scores에 저장된다. scores는 보통 10차원 벡터가 되겠다.
- margins = np.maximum(0, scores - scores[y] + delta) : scores[y]가 정답 클래스의 점수이다. margins는 모든 클래스의 점수에서 정답 클래스의 점수를 빼고 margin을 더한 값에 대한 벡터가 된다.
- margins[y] = 0 : 정답 클래스의 LOSS를 0으로 만든다.
지금까지 구한 loss function에는 문제가 있다.
L = 0 이 되는 W를 찾았다고 하면 W는 유일한 해를 갖는가?

loss 값이 0이 되는 W를 찾고 나서, W를 두 배 증가시켜도 여전히 loss 값이 0이 된다.
Weight Regularization
학습 데이터는 제외하고 어떤 W 값이 좋은 것인지에 대한 개념이다.
$$ L = \frac 1 N \sum_{i=1}^N \sum_{j \neq y_i}^{} max(0, f(x_i;W)j - f(x_i;W){yi} + 1) + \lambda R(W) $$
식을 보면 새로운 term이 하나 더 붙었다. 여기서 람다는 얼마나 세게 regularization을 할건지 정하는 Hyperparameter이다. 이 값을 너무 크게 정하면 앞 부분의 train 성능이 줄어들 수 있다. train 성능이 줄더라도 처음보는 test set에 대한 test 성능은 더 좋아진다.
가중치 정규화는 머신러닝 모델에서 학습된 가중치가 너무 커지지 않도록 제약을 가하는 방법이다. 가중치가 너무 커지면 모델이 데이터에 과하게 맞추게 되어 과적합이 발생할 수 있다. 정규화는 모델이 훈련 데이터에 과하게 적응하지 않고, 새로운 데이터에 더 잘 일반화 할 수 있도록 돕는다.
가중치 정규화는 손실 함수에 가중치에 대한 패널티 항을 추가하여 이루어진다. 이 패널티 항은 가중치의 크기를 제약하고, 람다가 패널티 항의 강도를 조절하게 된다.
수식의 R(W)는 가중치 정규화 항으로 가중치 W의 크기를 측정하고, 그 크기에 패널티를 부과하는 함수이다. 주로 L1 정규화와 L2 정규화가 사용된다.
Softmax loss
Score는 가중치 W와 X의 내적으로 구했다. Score를 각 클래스에 대해 normalized 되지 않은 확률로 볼 수 있다.
$$ P(Y=k | X=x_i) = \frac {e^{sk}} {\sum_je^{sj}} \ where\ s = f(x_i;W) $$
- P( Y = k | X = x_i) = X가 x_i 일 때 Y가 k라는 클래스에 속할 확률로, 조건부 확률이다.
- 분자는 k 클래스에 대한 score 값을 지수 함수로 변환한 값이다.
- 오른쪽의 식의 분모는 모든 클래스에 대한 score의 합을 지수 함수로 변환한 값들의 합이다.
- 지수 함수로 변환한 이유는 정규화에 있다. score를 양수로 변환하고, 큰 값을 더욱 강조하기 위함이다.
- 여기서 P가 likelihood가 된다.
- Likelihood는 주어진 데이터가 해당 확률 모델에서 나올 가능성을 나타낸다. 왜 P가 Likelihood가 되는지 생각하기 전에, Likelihood가 무엇인지 알아보자.
- 모델이 주어진 데이터를 얼마나 잘 설명하는지를 나타내는 척도이다. 머신러닝에서의 목표는 주어진 데이터에 대해 모델이 예측한 결과가 실제로 얼마나 맞는지를 측정하는 것이다. 이를 가능도로 나타내는 것이며, 주어진 데이터에 대한 모델의 출력을 가장 잘 맞는 파라미터를 찾아가는 과정이 모델 학습이다.
- P가 왜 Likelihood가 되냐면, 모델이 주어진 입력 x_i에 대해 어떤 클래스 k를 맞출 확률이 P이다. 이 P는 모델의 파라미터 W에 따라 달라지며, 학습 과정에서 P의 값을 최대화해야 한다.
log likelihood가 최대가 되려면, 즉 loss function 으로는 negative log likelihood가 최소가 되어야 한다. 왜냐하면 log likelihood는 최대화해야 하고, loss function은 최소화 해야 한다. 따라서 negative log likelihood를 사용하는 것이고 식은 아래와 같다.
$$ L_i = -log \ P(Y=y_i | X=x_i) $$
여기서 확률 P는 위의 식에서 바꿔쓸 수 있으므로 최종 식은 아래와 같다.
$$ L_i = - log(\frac {e^{Sk}} {\sum_je^{Sj}}) $$
이 함수가 바로 Softmax가 된다.
Softmax loss 예제

- W, x의 내적한 값으로 score를 얻는다.
- 얻은 score들을 unnormalized log probabilities로 보고 exponential을 취해서 unnormalized probabilities를 구한다. 예를 들어 e^3.2로 바꾸는 것이다.
- unnormalized probabilities를 normalize 시키기 위해서 unnormalized probabilities의 합으로 나눠준다.
- 이제 확률을 얻었고, 이 확률에 negative log를 취함으로써 loss 값을 정의할 수 있다.
- 이 값이 Softmax loss가 된다.
SVM loss와 마찬가지로 추가적인 이해를 위해 몇 가지 질문이 있다.
- What is the min/max possible loss L_i?
- loss function의 최솟/최댓값은?
- 최솟값의 경우는 0이 된다. 제대로 예측을 하면 unnormalized probabilities가 1이 되어서 log를 취하면 0이 된다.
- 최댓값은 무한대가 된다.
- usually at initialization W are small numbers, so all s ~= 0. What is the loss?
- W가 굉장히 작으면 score가 0에 가깝게 된다. 이 경우 loss는?
- score가 0에 가깝게 되면 exponential 값은 1이 되고 확률로 바꾸면 1/클래스 수가 된다. 이게 log에 들어가게 된다.
Hinge loss(SVM) vs Cross-entropy loss(Softmax)
3. Optimization

위의 그림을 잘 알아두자.
regularization term은 weight에 대해서만 계산한다. 여기서 정규화 항은 모델의 가중치에 대해 계산된다는 뜻은 데이터와 상관 없이 모델의 파라미터인 가중치에 대해 페널티를 부과하는 용도로만 사용된다는 의미이다.
weight W와 이미지 입력값인 x_i를 통해 score function을 계산할 수 있고 loss는 score function의 값과 실제 정답인 y_i를 이용해서 계산할 수 있다.
Random Search
임의로 가중치 W를 선택하여 이 가중치에 대한 loss를 구하는 것이다. 실제로 사용되지는 않고 loss가 가장 적은 W를 선택하게 된다.
Follow the slope
경사를 따라 내려가는 방법이다. Gradient Descent는 어떤 사람이 산 중턱에 있고 눈을 가린채 한 발 한 발 딛어보면서 한 발 앞의 경사만 가지고 산을 내려가는 것으로 비유할 수 있다.
수식은 다음과 같다.
$$ \frac {df(x)} {dx} = \lim_{h\to0}\frac {f(x+h) -f(x)} {h} $$
한 발 앞의 경사가 수식에서의 h가 되고, 한 발 내딛었을 때 경사가 얼마나 변했는지를 계산해서 Gradient(기울기)를 구할 수 있다.
다차원에서 gradient는 편미분 (partial derivatives) 값을 갖는 벡터로 표현할 수 있다.
- 편미분은 다변수 함수에서 하나의 변수에 대해서만 미분하는 것을 의미한다.
- 다차원 함수는 다변수 함수와 같은 말이고, 다변수 함수에서 Gradient는 각 변수에 대한 변화율(편미분)을 모아서 만든 벡터로 볼 수 있는 것이다.
한 발자국씩 앞으로 내딛는 수치적인(numerical) 방법은 다음과 같이 이루어 진다.

- 현재 W 값에 대해 loss를 계산한다.
- W의 각 차원에서 한 발자국, h만큼 움직였을 때 loss를 계산한다.
- 현재 loss와 한 발자국, h만큼 나아갔을 때 loss의 차를 h로 나눈다.
- W의 모든 차원에 대해 반복한다.
이 방법은 수학적으로 너무 느려서 사용하지 않는다.
대신 해석적으로 Analytically 접근할 수 있다. 미분의 개념을 사용하는 것이다.
우리가 사용할 것은 Loss function을 W에 대해 미분한 값이다. 손실 함수의 값을 최소화하기 위해 손실 함수의 W에 대한 변화를 측정해서 W를 어떻게 변경해야 손실이 줄어드는지 알아내야 한다. 바로 이때 W에 대한 미분값, 즉 Gradient가 사용된다.
정리하자면, 수치적으로 gradient를 구하는 방법은 구현하기는 쉽지만 너무 느리다. 해석적으로 gradient를 구하는 방법은 정확하고 빠르지만 error가 발생할 가능성이 있다.
그래서 항상 해석적으로 gradient를 사용하지만 수치적으로 gradient를 구해서 이 값이 실제로 증가하거나 감소하는지 확인하게 되고 이 과정을 gradient check라 한다.
Gradient Descent (경사하강법)
weight gradient가 증가하는 반대 방향으로 움직여서 최솟값을 찾아 가는 방법이다.

그림에서 W_1, W_2는 각각 두 개의 독립적인 가중치이다. 경사 하강법에서는 W를 반복적으로 업데이트하여 손실 함수를 최소화하는 것이 목표이다.
그래프는 손실 함수의 값을 시각적으로 표현한 것이다. 바깥 쪽 빨간 부분이 손실 함수의 값이 가장 큰 부분이고 파란 부분이 가장 작은 부분이다.
흰색 화살표가 가리키는 방향은 negative gradient 방향으로, 손실이 감소하는 방향이다. 이 방향으로 이동하면 손실 함수의 값이 점점 작아지게 되고, 최종적으로 최솟값에 수렴하게 된다.
negative gradient는 손실 함수를 가중치 W에 대해 미분한 값의 음수로, 손실 함수가 가장 빠르게 감소하는 방향으로 가중치를 업데이트 한다.
가장 기본적인 gradient descent의 코드를 보자.
# Vanilla Gradient Descent
while True:
weights_grad = evaluate_gradient(loss_fun, data, weights)
weights += -step_size * weights_grad # perform parameter update
loss 함수와, data, weight를 이용해서 가중치의 gradient를 구하고 가중치 gradient의 반대 방향으로 step_size를 반영하여 가중치를 조절하는 코드이다.
step_size는 학습률(learning rate)라고도 하며, 한 번의 업데이트에서 얼마나 크게 가중치를 변화시킬지를 결정하는 hyperparameter이다. wiehgt_grad는 손실 함수의 gradient로, 손실 함수가 가장 급격하게 증가하는 방향을 가리킨다.
전체 학습 데이터를 사용하는 것이 아닌 일부분을 사용하여 gradient descent를 수행하는 Minibatch 방식도 존재한다.
# Vanilla Minibatch Gradient Descnet
while True:
data_batch = smaple_training_data(data, 256) # sample 256 examples
weights_grad = evaluate_gradient(loss_fun, data_batch, weights)
weights += -step_size * weights_grad # perform parameter update
코드는 256개의 training data에서 smapling 데이터를 가지고 batch 단위로 학습을 진행하는 코드이다.
일반적인 미니 배치 사이즈는 32/64/128 개의 학습 데이터를 사용한다. GPU 메모리에 맞게 설정한다.

learning rate(step_size)도 상당히 중요하다. 그림을 보면 learning rate가 너무 크면 발산하고 너무 낮으면 너무 천천히 감소해서 학습 시간이 오래 걸린다. learning rate가 큰 경우 loss 값이 최솟값에 수렴하지 않고 local minimum에 수렴하는 경우가 있다.
4. Image Features
이미지에서 feature를 추출하는 방법을 알아보자.
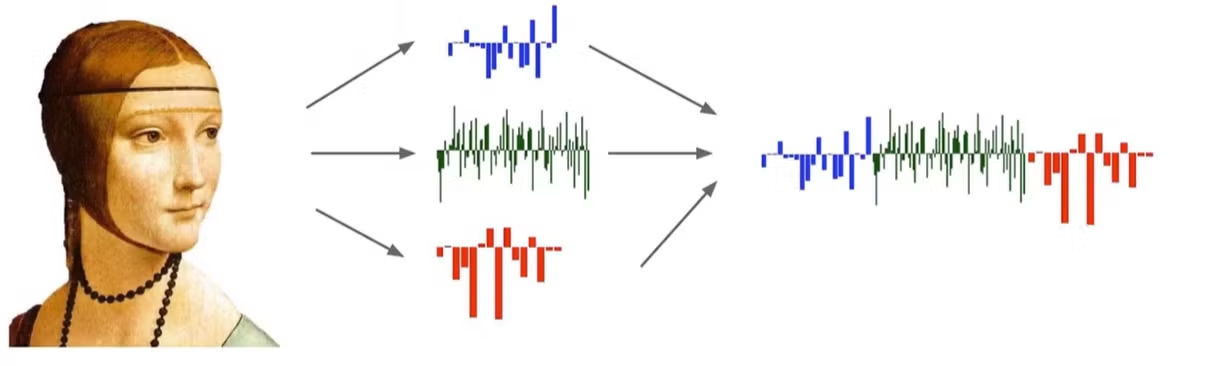
컴퓨터 비전 문제에서 보는 raw 이미지는 RGB 채널로 이루어져 있다. 각각 빨간색, 파란색, 초록색이 얼마나 포함되는지를 뽑고 순서대로 이어서 큰 벡터 형태로 표현할 수 있다.

Color Histogram 방식으로도 이미지를 볼 수 있는데, 한 이미지가 일정한 색을 얼마나 가지고 있는지에 대한 통계적 요약이다.
HOG / SIFT Features
이미지는 edge들의 조합으로 표현된다는 가정으로 시작하여, 8X8 픽셀을 갖는 지역에서 edge들의 정보를 요약하는 것을 말한다.

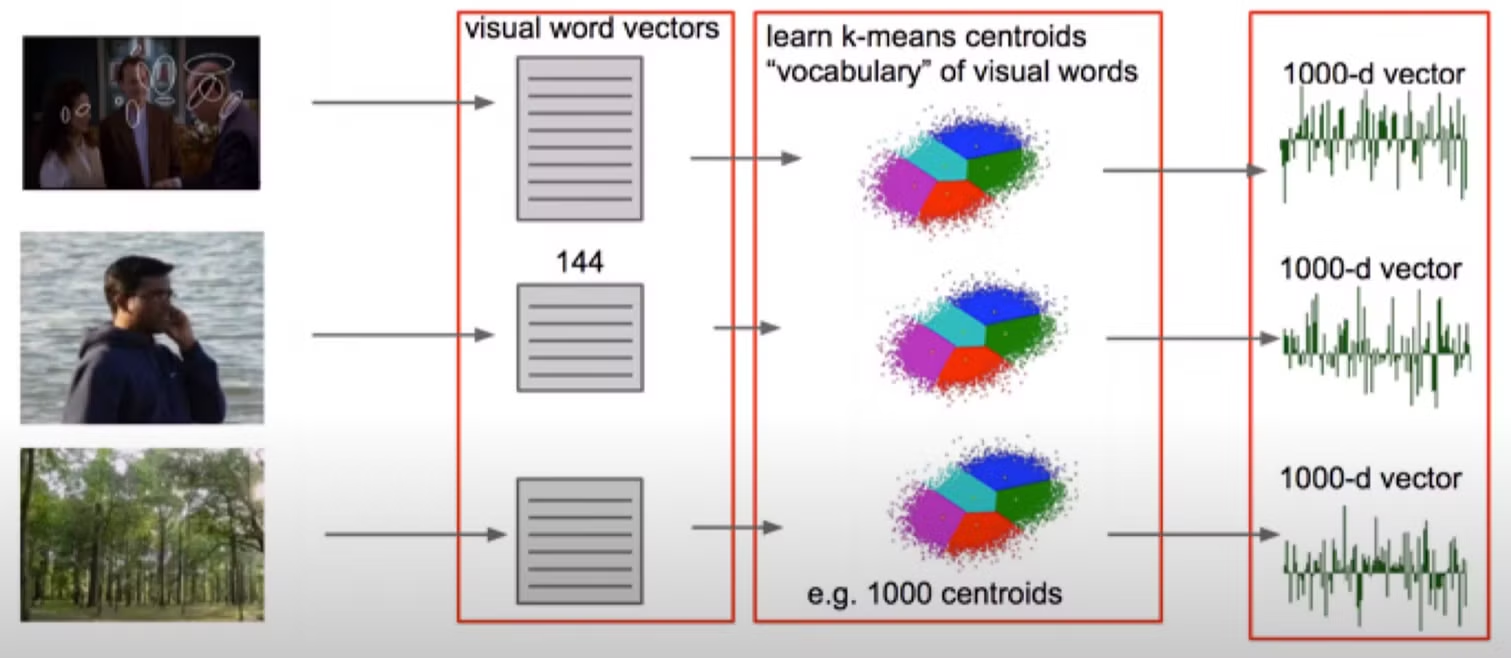
Bag of Words
각각의 raw 이미지를 visual word vector로 표현하기 위해 숫자로 이루어진 벡터 형태로 임베딩 하는 방법이다. 임베딩 한 후 k-means 알고리즘으로 1000 개의 중심점을 갖도록 학습시킨다. 그럼 각 이미지에 해당하는 visual word들을 1000 차원의 벡터로 표현할 수 있다.
'AI > CS231n' 카테고리의 다른 글
| [DSBA] CS231n - 7. Convolutional Neural Networks (1) | 2024.11.10 |
|---|---|
| [CS231n] Training Neural Networks Part 1 (11) | 2024.10.09 |
| [CS231n] 4. NeuralNetwork, Backpropagation (5) | 2024.10.03 |
| [CS231n] 이미지 분류의 pipeline과 K-NN based 이미지 분류, Cross Validation (3) | 2024.09.25 |