1. Introduction
Hardware basics
- 하드디스크보다 메모리가 훨씬 빠르다.
- 그러나 메모리의 양이 매우 적기에 양을 나누어서 메모리에 넣고, external sort를 수행해서 inverted index를 만드는 방식으로 작동하게 된다.
- 디스크에서 정보를 찾는 seek time은 굉장히 느리다. 참고로 seek는 트랙을 찾는 것이고 섹션을 찾는 rotate는 비교적 빠르다.
- 모든 operation을 디스크를 거치지 않고 메모리에서 하면 굉장히 빠르다.
- 한 번 트랙을 찾으면 최대한 많이 읽어오는 것이 유리하고 그래서 block 단위로 저장하는 것이 좋다.
- Fault tolerance는 비싸다.
RCV1 collection
- 정보 검색을 테스트하기 위해 원래 셰익스피어의 희곡을 사용했는데 양이 너무 적었다.
- 그래서 1995~1996년의 기사를 수집해서 RCV1 collection을 만들었다.
- 문서의 수 : 800,000 문서당 토큰 수 : 200 terms(word types) : 400,000 bytes per token : 4.5 bytes per term : 7.5 non-positional postings : 100,000,000그래서 token 길이의 평균은 더 짧고 term은 더 길다.
- 이렇게 구성되는데, token은 인스턴스로 같은 단어를 다르게 보고 term은 word type을 의미한다. 왜 token이 더 짧고 term이 더 긴지 생각해보면, token은 중복이 많이 일어나는 단어들이 많다. 그렇다면 token의 분포를 생각해봤을 때 중복이 많은 단어의 비율이 더 높을테고 중복이 많은 단어는 a, the, to 와 같은 더 짧은 단어의 비율이 훨씬 높을 것이다.
2. BSBI
inverted index를 만들어보자.

- 문서를 open 해서 모든 단어를 document ID와 함께 적는다.
- 메모리에서 단어를 정렬하고 여러 문서에 나오는 단어에 대해 하나로 합치면서 inverted index를 만들면 된다.

이렇게 index를 만들었는데 전체 index를 메모리에 올릴 수 없다. 그래서 메모리에 올릴 수 있는 만큼만 sorting 해서 올리고 마지막에 합치는 작업만 잘 해주는 방식으로 index를 만들 수 있다. 메모리에 올릴 수 있는 만큼만 올려서 정렬하고 inverted index를 부분 부분 만들어서 합치는 것이다.
이를 위해서는 일단 external sorting algorithm이 필요하다.
non-positional posting 100,000,000 개를 정렬해야 한다고 생각해보자. 각 posting은 termID, docID, term frequency로 12 byte를 가지고 있다.
block을 10,000,000으로 정의하고 10개의 block으로 나누고 각 block에 다음 알고리즘을 수행하면 된다.
- postings 모으기
- 메모리에서 정렬하기
- disk에 쓰기
정렬된 blcok을 메모리에 다시 쓸 때 merge가 일어나게 된다.

병합은 병합할 두 blcok에 각각 포인터를 두고, 같은 단어라면 둘 다 결과에 쓰기. 다르다면 알파벳 순서가 빠른것부터 결과에 쓰고 포인터 증가.
위와 같은 방식으로 merge 할 수 있다. 따라서 우리는 그냥 디스크에 posting 들을 나열해두고 inverted index를 만들 때 하나의 리스트로 만들면 된다.
병합할 때 결과가 왜 저렇게 되는지 merge sort를 알아두자.
알고리즘은 다음과 같다.

3. SPIMI
BSBI와 같은 sort based 알고리즘은 inverted index를 만들때 disk에 두 번 접근한다는 단점이 있다. 또, BSBSI는 termID를 가지고 docID를 찾는 방식이다. 따라서 term과 termID로의 매핑을 위한 dictionary가 또 필요하다.
그래서 나온게 Single Path In Memory Indexing이다. 기본적인 아이디어는 termID를 매핑시키지 말고 한 번에 찾을 수 있도록 하는 것이다.
핵심 아이디어는 다음과 같다.
- 각 block마다 분리된 dictionary를 만든다. term-termID mapping을 유지하지 않기 위해서이다.
- 정렬하지 않는다. posting 발생 순서대로 바로 posting list에 추가한다.
위의 두 아이디어를 가지고 각 block마다 완전한 inverted index를 만들 수 있다. 이러한 분리된 index들은 big index로 병합될 수 있다.

각 block마다 output file과 dictionary를 만들고 다음 과정을 수행한다.
- 토큰이 dictionary에 존재하지 않으면 그 term을 dictionary를 추가하고 posting list에 넣어둔다.
- dictionary에 존재한다면 그 token이 존재하는 posting list를 가지고 온다.
- 토큰의 docID를 posting list에 추가한다.
- 메모리가 가득 찰때까지 1~3을 반복한다.
- 메모리가 가득 찼다면 딕셔너리를 정렬하고 disk에 쓴다.
BSBI VS SPIMI
BSBI
- block 단위로 문서를 메모리에 올리고 토큰화와 해당 문서 ID를 페어로 만든다. 그 후 정렬하여 디스크에 부분적인 inverted index를 쓰고, 모든 block에 대해 수행한 후 index 들을 merge 한다.
- 중간 정렬이 필요하고 Term을 termID로 변환하여 사용한다.
SPIMI
- block 단위로 문서를 메모리에 올리고 올린 만큼 딕셔너리를 구축한다. 메모리가 가득차면 딕셔너리를 디스크에 쓰고 다음 문서에 대해 수행한다. 마지막에 merge만 해주면 된다.
- 중간 정렬이 필요하지 않다. 마지막에 정렬 후 merge만 해주면 된다.
경우에 따라서는 term, posting을 압축할 수 있다.
4. Distributed indexing
정보 검색은 전 세계의 웹사이트를 대상으로 한다. 그만큼 엄청나게 많고 local disk에 도저히 넣을 수 없다.
슈퍼컴급 서버를 계속 늘리는 것도 비효율적이고 flexible하지 않다.
그래서 PC급 서버를 여러 대 나누어서 분산시키는 환경이 좋다.
Map Reduce
검색을 하거나 indexing을 할 때 여러 컴퓨터에게 나눠주고 일을 처리하도록 해야 한다. 이를 위해서 일을 분담해줘야 하고 결과를 통합해서 넘겨주는 역할도 필요하다.
그 역할을 하는 컴퓨터가 master 머신이다. master 머신이 job controll을 하고 indexing 시키는것도 여러 머신에 나눠서 시키고 필요하다면 다시 모으는 역할을 하며 이를 Parallel task라 한다. Parallel task는 두 가지로 나뉜다.
Parsers : 토큰으로 나누기
Inverters : inverted index로 만들기
disk에서는 block 별로 문서를 나누었는데 여기서는 PC 별로 문서를 나눠야 하므로 split로 나눈다.

이 그림이 핵심이다.
- 전세계에서 모은 문서를 split으로 나눈다.

2. parser가 문서를 읽어서 문서 번호를 달고 토큰화한다. term, docID pair로 만드는 것.

a-f는 토큰의 이름이 a-f로 시작한다는 것이다.
3. inverter가 a-f로 시작하는 토큰을 다 모으고, 또 다른 inverter는 g-p 토큰을 다 모으고 q-z도 다 모은다.
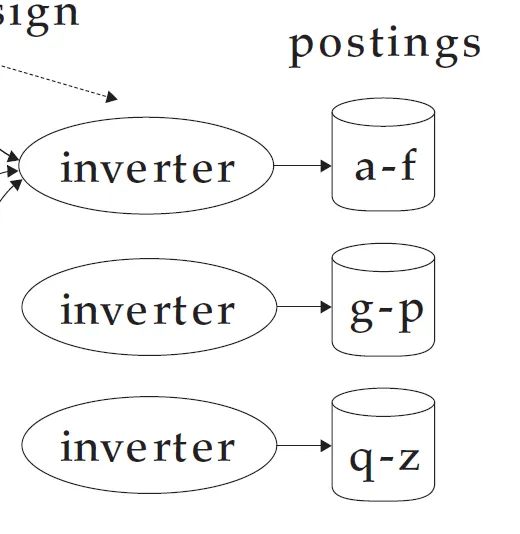
그리고 모은 posting들로 sort 하고 posting list로 만든다.
이제 유저가 boy 쿼리를 입력한다면 쿼리를 담당하는 프로그램이 a-f가 저장된 포스팅에 보내면 된다.
각 split에 대해 parser가 토큰으로 뽑아내는 과정을 map phase라 하고 a-f, g-p, q-z 토큰으로 나눈걸 segment files, 토큰을 다시 모아서 inverter가 inverted index를 만드는 과정을 reduce phase라 한다.
master, parser, inverter 세 종류만 있으면 된다.
위의 아키텍쳐를 MapReduce라 한다. 이 환경에서 PC 하나가 죽으면 죽은 PC를 빼고 다시 split 해도되고 replace 해도된다.
검색의 특성상 정확도보다는 유사한 결과를 많이 줘야하기에 하나가 고장이 나도 괜찮다.
parser, inverter 모두 똑같은 알고리즘으로 여러 대가 돌아가기에 단순하다.
5. Dynamic indexing
지금까지 한 indexing은 문서가 변하지 않는다고 생각하였다.
그러나 페이지는 계속 변하고 그 변화를 처음부터 다 문서를 모으고 indexing하는 작업은 굉장히 비용이 많이 든다.
그래서 업데이트된 내용만 모아서 indexing하는 기술을 dynamic indexing이라 한다.
가장 간단한 접근법은 main index를 disk에 넣고 매일 collecting하면서 새로운 문서는 메모리에 넣는 것이다. 쿼리가 들어오면 disk에서 찾고 없다면 메모리에서 찾는다.
delete를 할때는 document에 valid bit를 넣어두고 검색 결과에 포함되더라도 valid bit가 0이면 검색 결과에 출력하지 않는다.
자주 merge가 일어나면 main index에 문제가 생길 수 있다. 그래서 가능하면 빠르게 비용도 적게 merge해야 한다.
그 방법이 Logarithmic merge이다.
Logarithmic merge
- 새로운 document의 smallest index를 $Z_0$라 하고 메모리에 저장한다.
- 큰 index는 $I_0, I_1, ...$이라 하고 디스크에 써둔다.
- $Z_0$가 n보다 커지면 디스크에 $I_0$로 쓴다.
- 혹은 $I_0$가 이미 존재하면 $I_0$를 $Z$에 merge 시킨다.
예를 들어 I가 0010이고 Z0가 1로 새로 들어왔다면 I가 0011이 된다. 또 Z0가 어느정도 찼다면 I에 넣어야 하는데 I0, I1이 모두 11이기에 I0 I1을 Z0에 merge 한다. 그럼 Z에는 1 + I0 + I1 = 1 + 1 + 10 = 100이 된다.

이 알고리즘을 잘 이해해보자.
I0의 크기를 n이라 하면, I1은 2n, I2는 4n, …, Ik의 크기는 2^kn이 된다.
새로운 데이터가 들어오면 I0에 저장된다. I0가 가득 차면 I1과 병합하고, 병합했는데 I1이 가득차면 I2와 병합한다. 이 과정이 계속된다.
이 과정이 계속 반복되면 각 레벨의 인덱스 크기가 이전 레벨의 2배가 된다.
Logarithmic merge
- index의 수는 최대 O(log T)이다. T는 posting의 전체 숫자이다. T를 2진수로 표현하는데 log T 길이면 충분하기 때문이다.
- index를 구성하는데 O(T log T)의 시간이 든다.
- 트리라고 생각하면 되는데, 가장 작은 index 병합, 그 다음 index 병합, … 이렇게 하면 트리의 높이인 log T 번 병합이 일어나고 병합이 T만큼 걸린다.
- 조금 다르게 생각하면 T개의 posting에 대해 log T 번의 merge가 일어난다.
- 일반적인 merge를 생각해보면 모든 index의 size가 a로 고정된다. 그리고 모든 index를 한 번에 하나의 큰 index로 병합할텐데, 그 과정에서 a + 2a + 3a + .. + Ta 만큼 병합이 일어난다. 이는 O(T^2) 만큼의 병합이 일어난다는 뜻이다.
- 따라서! Logarithmic merge가 시간적으로 훨씬 빠르다.